相关链接:
Abstract
RULER-HQA的准确率分数。即使采用了长上下文持续预训练和外推技术的模型,也无法保持一致的性能。相比之下,使用RL的MEMAGENT仅表现出微小的性能下降。
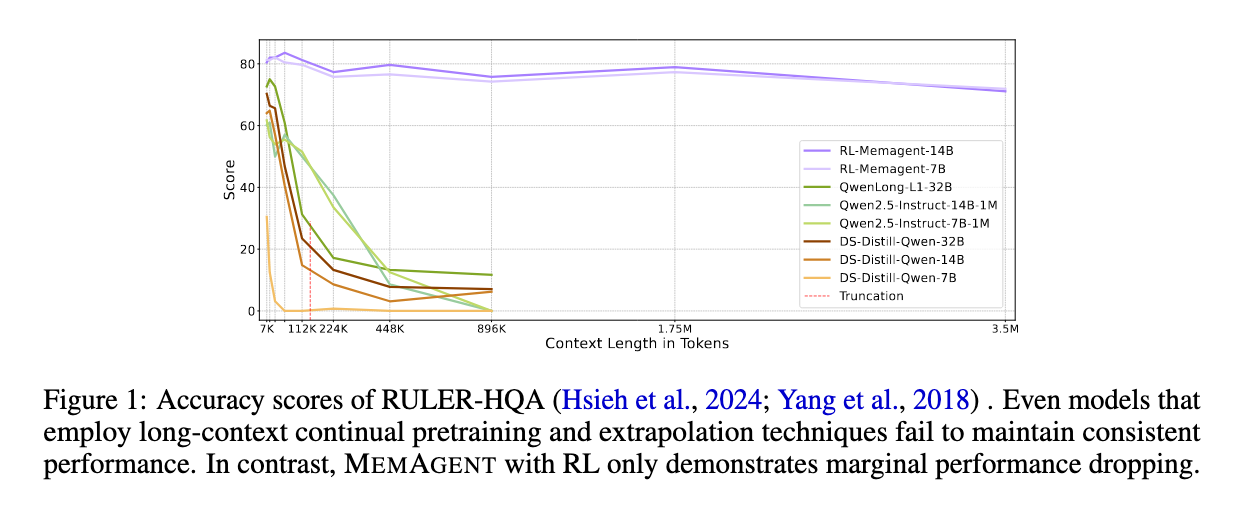
尽管通过长度外推、高效注意力和记忆模块取得了改进,但在外推过程中处理无限长的文档而不出现性能下降,仍然是长文本处理中的终极挑战。为了解决这个问题,我们引入了一种新颖的智能体工作流——MEMAGENT,它分段处理文本并通过覆盖策略更新记忆,通过增强的记忆管理来应对长上下文任务的挑战。我们进一步扩展了DAPO算法,以端到端的方式直接优化记忆能力,通过独立上下文的多对话生成促进训练。实验结果表明,MEMAGENT具有卓越的长上下文能力,能够将上下文从8K外推到3.5M的问答任务,性能损失小于10%,并在512K的NIAH测试中达到超过95%的准确率
Introduction
如何有效地处理长上下文——处理整本书籍、执行多步复杂推理链,或管理智能体系统的长期记忆——所有这些复杂任务都可能产生海量文本,迅速超出当前LLM的典型上下文窗口大小。
- 长度外推方法:通过移动位置嵌入来扩展模型的上下文窗口,并辅以继续预训练。尽管潜力巨大,但由于在处理极长文本时具有O(n²)的计算复杂度,这些方法常常遭受性能下降和处理速度慢的问题。
- 利用稀疏注意力和线性注意力机制来降低注意力复杂度,从而更高效地处理更长的序列。通常需要从头开始训练,存在固有的缺陷,例如线性注意力在并行训练方面面临困难,或者稀疏注意力依赖于人工定义的模式。
- 上下文压缩:旨在token级别或通过外部记忆插件模块来压缩信息。这类方法常常在外推方面遇到困难,并且需要集成额外的模块或上下文操作,这不可避免地会干扰标准的生成过程,并阻碍兼容性和并行化。
目标:
- 处理无限长度的文本
- 在扩展时无显著性能下降
- 具有线性复杂度的高效解码
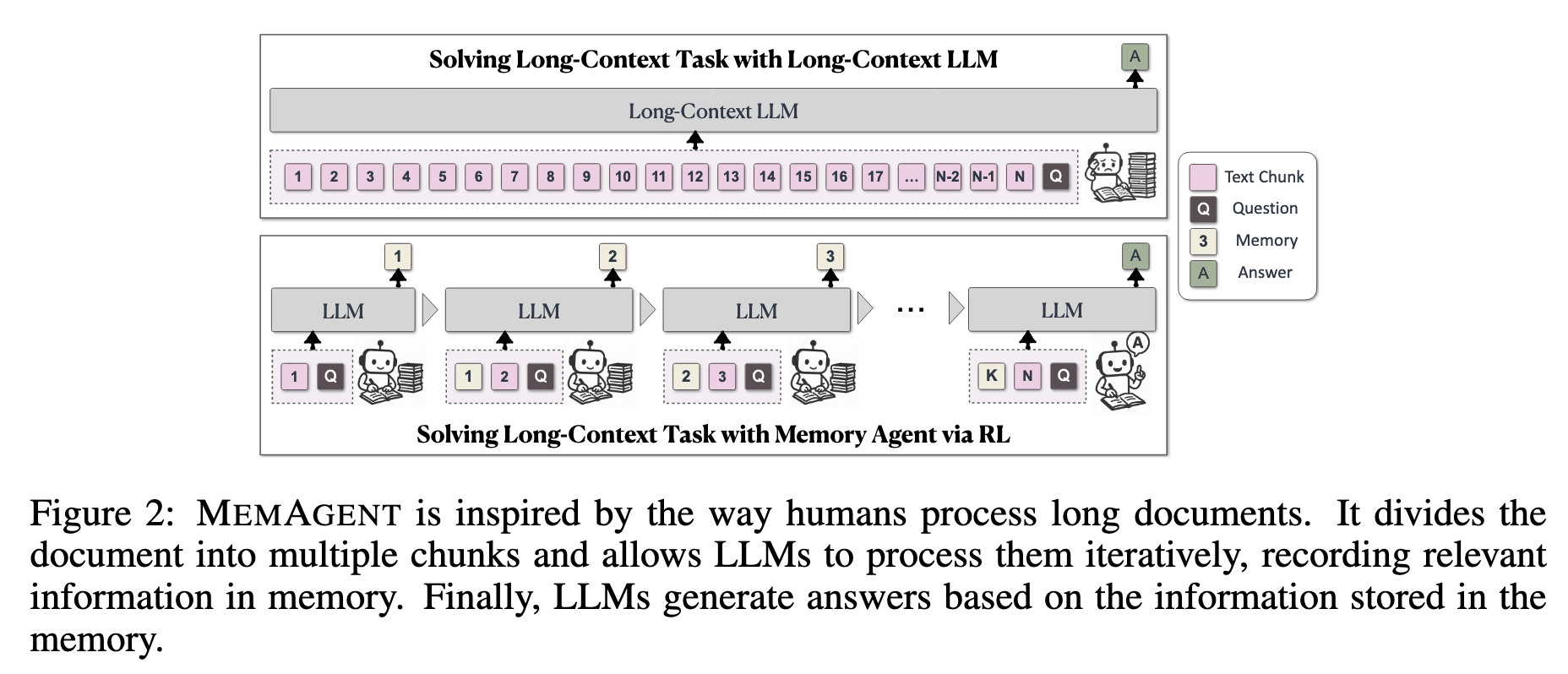
MEMAGENT的灵感来自于人类处理长文档的方式。它将文档分成多个块,并允许llm迭代地处理它们,在内存中记录相关信息。最后,llm根据存储在内存中的信息生成答案。
MEMAGENT方法提出将每个上下文独立的对话视为一个优化目标。基于DAPO算法,实现了多对话DAPO,以通过可验证的结果奖励来优化任意智能体工作流。
- 使LLM能够在推理期间以线性时间复杂度,在有限的上下文窗口内处理任意长的输入,克服了长上下文处理中的一个重大瓶颈。
- 设计了一个智能体工作流来实现这种机制,并提出了一种使用多对话DAPO算法的端到端训练方法。
- 通过实验证明,基于RL训练的方法使模型能够外推到极长的文档,且性能下降最小,从而突破了当前长上下文LLM系统所能实现的界限。
Methodology
- 把长文档切成N份chunk
- 每次给模型看:
- 当前问题
- 上一个chunk得到的memory
- 当前chunk内容
- 模型输出一份基于当前chunk的内容增量的memory覆盖旧的
- 所有chunk读完后再输入问题、最终memory
- 基于最终memory输出答案
关键点:
- memory固定长度
- memory属于普通token
- 每轮是覆盖写入而不是无限追加
受限带宽下的信息压缩,边读边做笔记
要求模型每轮做出决策:
- 哪些信息需要保留
- 哪些细节可以丢
- 哪些旧信息该被新信息替换
The Memagent Workflow: RL-Shaped Memory For Unbounded Contexts
MEMAGENT不将任意长的文档视为一个整体块,而是视为一个受控的证据流。在每个步骤,模型精确地看到两样东西:下一块文本和一个紧凑的、固定长度的记忆,该记忆总结了到目前为止所有被认为重要的信息。关键的是,记忆只是上下文窗口内的一串普通token,因此基础LLM的核心生成过程保持不变。
阅读一个新的文本块后,模型会用更新后的记忆覆盖之前的记忆。因为记忆长度从不增长,每个文本块的总计算量保持在O(1),端到端的复杂度严格与文本块数量成线性关系。
将覆盖决策形式化为一个强化学习问题:智能体因保留以后会有用的信息并丢弃会浪费宝贵token的干扰项而获得奖励->模型学会了在积极压缩的同时保留对答案关键的事实。
- 在上下文处理模块中,模型迭代处理文本块,使用提示模板更新记忆。
- 当证据流耗尽,调用最终的答案生成模块。模型仅依据问题陈述和记忆来生成其框定好的答案。
MEMAGENT主要好处:
- 无限长度:文档可以长达数百万token,因为它作为流处理
- 无性能明显衰退:RL鼓励记忆精确地保留所需信息,产生近乎无损的外推
- 线性成本:恒定的窗口大小意味着解码时间和内存消耗随输入长度线性增长
Training Memagent With Multi-Conv RL
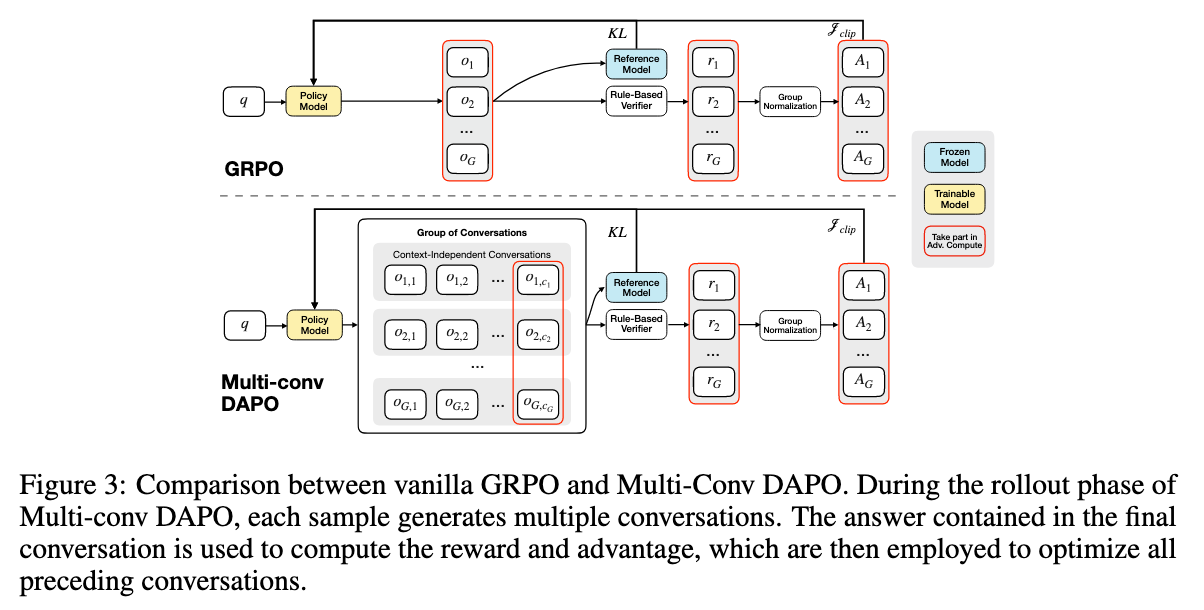
GRPO与多conv DAPO的比较。在Multi-conv DAPO的推出阶段,每个示例都会生成多个会话。最后对话中包含的答案用于计算奖励和优势,然后用于优化之前的所有对话。
每轮上下文里只放:
-
当前问题
-
当前 memory
-
当前 chunk 每一轮可以视为一个独立的conversation,最终reward只有最后回答时才能拿到,但是每一轮的memory update都要对最终答案负责
-
用RLVR来训练MEMAGENT
-
采用DAPO作为训练算法
由于MEMAGENT方法的性质,它为单个查询生成多个上下文无关的对话,如图2所示,因此将每个对话视为一个独立的优化目标。这种方法需要将损失计算从传统的(组、令牌)结构扩展到新的(组、对话、令牌)维度,如图3所示。
- 一个样本 rollout 出多段 conversation
- 最后一段回答产生 outcome reward
- 这个 reward 再分配回前面所有 memory update conversation
- 从而让每一轮“写记忆”的行为都得到优化
策略模型 为一个输入采样一组个独立的响应。
设 表示对于给定样本 生成的对话数量 进一步分解为token级别的输出
统一应用于源自同一样本的所有对话,如公式1所示。遵循Dr.GRPO,不按标准差对优势进行去偏。 公式2描述了损失函数。
\mathcal{J}_{\mathrm{DAPO}}(\theta) = \mathbb{E}_{(q,a)\sim \mathcal{D},\{o_{i,j}\}_{i = 1}^{G}\sim \pi_{\theta_{\mathrm{old}}}(\cdot |q,a_{i,j - 1})} \\ {\qquad \left[\frac{1}{\sum_{i = 1}^{G}\sum_{j = 1}^{n_{i}}|o_{i,j}|}\sum_{i = 1}^{G}\sum_{j = 1}^{n_{i}}\sum_{t = 1}^{n_{i}}\left(\mathcal{C}_{i,j,t} - \beta D_{\mathrm{KL}}(\pi_{\theta}||\pi_{\mathrm{ref}})\right)\right]} \\ {\mathrm{where}\quad \mathcal{C}_{i,j,t} = \min \left(r_{i,j,t}(\theta)\hat{A}_{i,j,t},\mathrm{clip}\left(r_{i,j,t}(\theta),1 - \epsilon_{low},1 + \epsilon_{high}\right)\hat{A}_{i,j,t}\right)} \\ {\qquad r_{i,j,t}(\theta) = \frac{\pi_{\theta}(o_{i,j,t}\mid q,o_{i,j,<t})}{\pi_{\theta_{\mathrm{old}}}(o_{i,j,t}\mid q,o_{i,j,<t})}.} \end{array} \quad (2)$$ 遵循RLVR方案,使用由基于规则的验证器计算的最终结果奖励来训练模型: $$R(\hat{y},y) = \mathbf{1}_{is\_equiv(y,\hat{y})} \quad (3)$$ 其中 ŷ 是预测答案,而 y 指代真实答案。 ## Rethinking MEMAGENT From Autoregressive Modeling Perspectives 一个标准的自回归LLM将序列 $x_{1:N}$ 的联合似然分解为 $p(x_{1:N}) = ∏_{n=1}^N p(x_n | x_{1:n-1})$,隐含地假设每个过去的token(或至少其隐藏状态)必须保留在活动上下文中。 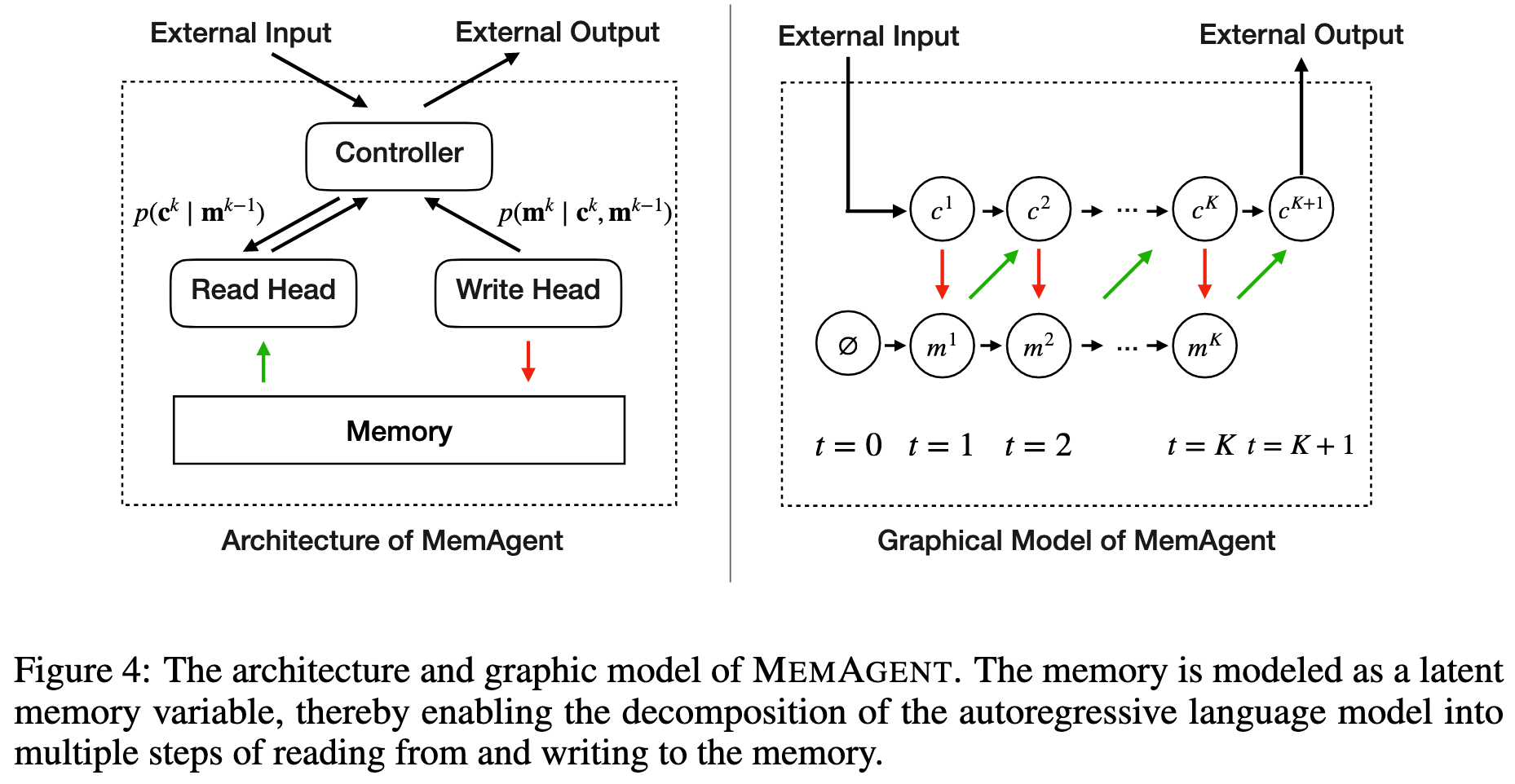 >MEMAGENT的体系结构和图形模型。记忆被建模为一个潜在的记忆变量,从而能够将自回归语言模型分解为从记忆中读取和写入的多个步骤。 MEMAGENT用一个固定长度的记忆 $m \in \mathcal{V}^M$ 替代了无界的历史记忆。 输入文本以K个连续的块 $c^1, ..., c^K$(每个长度 ≤ C)的形式流式传输给模型。在第k个块被读取后,模型用一个新向量 $m^k$ 覆盖记忆面板,该向量总结了到目前为止看到的所有证据。 因为 $|m^k| = M$ 是常数,每一步的计算和内存都是 $O(C + M)$,从而产生整体线性复杂度 $O(N)$。 引入潜在序列 $m^{1:K-1}$ 将原始似然分解为: $$p(\mathbf{x}_{1:N}) = \sum_{\mathbf{m}^{1:K - 1}}\prod_{k = 1}^{K}\underbrace{p(\mathbf{c}^{k}\mid \mathbf{m}^{k - 1})}_{\mathrm{read}}\underbrace{p(\mathbf{m}^{k}\mid \mathbf{c}^{k},\mathbf{m}^{k - 1})}_{\mathrm{write}}, \quad (4)$$ 基本情况为 $m^0 = \emptyset$。在每个块内部,我们仍然运行一个普通的Transformer解码器,但条件限制在一个恒定的上下文窗口 $(c^k, m^{k-1})$ 上。读取路径逐token分解,$p(c^k | m^{k-1}) = ∏_{i=(k-1)C+1}^{kC} p(x_i | x_{1:i-1}, m^{k-1})$,而写入路径以相同的自回归方式生成下一个记忆。 在表述中,模型在上下文上的读写操作构成了一个马尔可夫决策过程(MDP),强化学习的目标是优化此MDP获得的最终奖励。因此,MemAgent的学习目标是生成一个最大化奖励的读写记忆轨迹,这对应于学习一个以输入上下文为条件的、关于记忆状态的最优分布。这进一步从理论上阐明了本文RL公式与长文本建模之间的内在统一性。 # Experiments ## Experiments Setup - Qwen2.5-7B-Instruct - Qwen2.5-14BInstruct based on verl, two-stage curriculum RL strategy 1. 第一阶段的重点是使模型获得基本的记忆能力 2. 第二阶段训练模型将这些能力转移到更多样化的环境和具有挑战性的任务中。 训练设置:8K上下文 - 1024 query - 5000 context chunk - 1024 memory - 1024 output - remaining tokens reserved for the chat template benchmark: - RULER-HQA: 信息密度适中、长度可控 - LongBench-QA: 短任务,高信息密度 - NIAH: 长文本任务,低信息密度 - LongBench-SUM: long-context summay tasks baselines: - DeepSeek-R1-Distill-Qwen - Qwen-2.5-Instruct-1M - Qwen-2.5-Instruct - QwenLong-L1 ## Main Results ### RULER-HQA 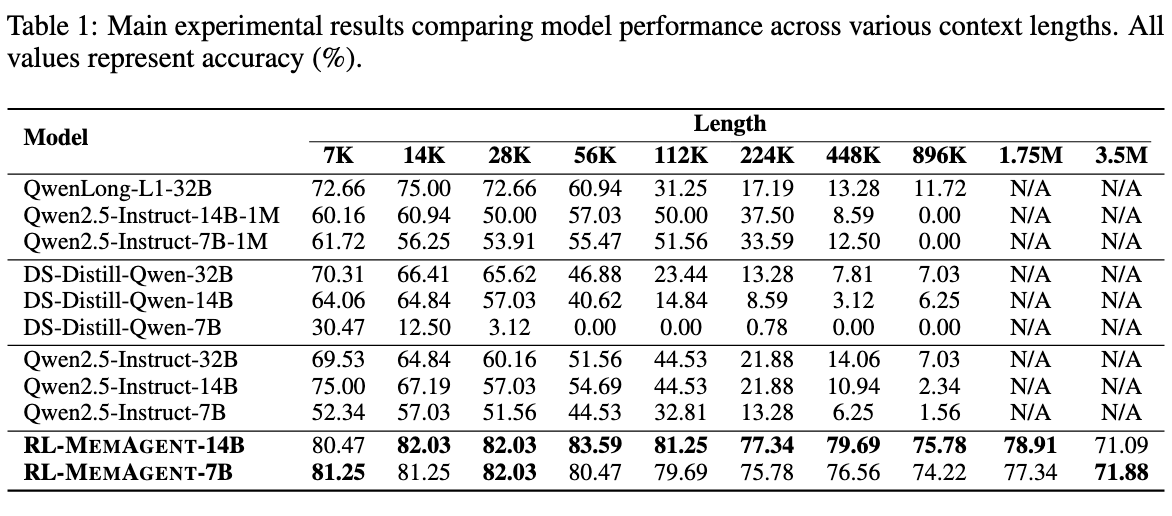 MEMAGENT表现出显著的长度外推能力,随着输入上下文长度的增加,性能只会轻微下降。相比之下,基线模型显示出明显的失效模式。DS-Distill-Qwen系列表现出快速的性能下降。QwenLong-L1在训练时间内保持了合理的性能,但在训练结束后性能会大幅下降。Qwen2.5-Instruct-1M系列在112K令牌时保持可接受的性能,但在达到理论1M令牌容量之前,在896K令牌时性能下降到零。这表明,尽管扩展了上下文窗口,但这些模型在超长上下文中难以有效地利用信息。 ### LongBench-QA 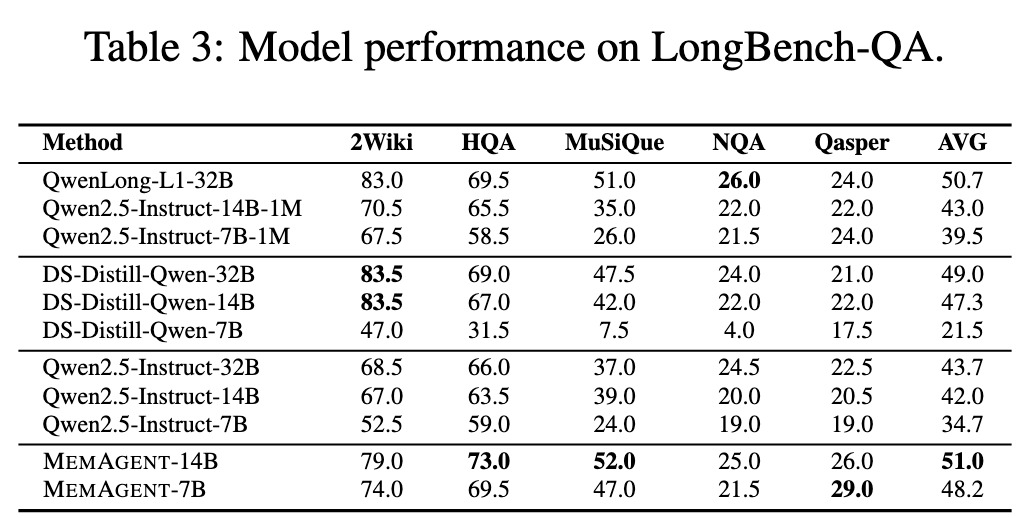 MEMAGENT表现出优越的整体性能,超过了更大的长上下文或推理模型。像DS-Distill系列和在复杂数据集上训练的QwenLong模型等推理模型,展现出强大的性能。相比之下,Qwen2.5-Instruct-1M系列相对于其骨干模型显示出有限的改进。这表明LongBench-QA更强调对文本的深度理解,而非简单的检索能力。MEMAGENT的性能证明了通过强化学习获得的记忆能力是具有泛化性的。 ### NIAH 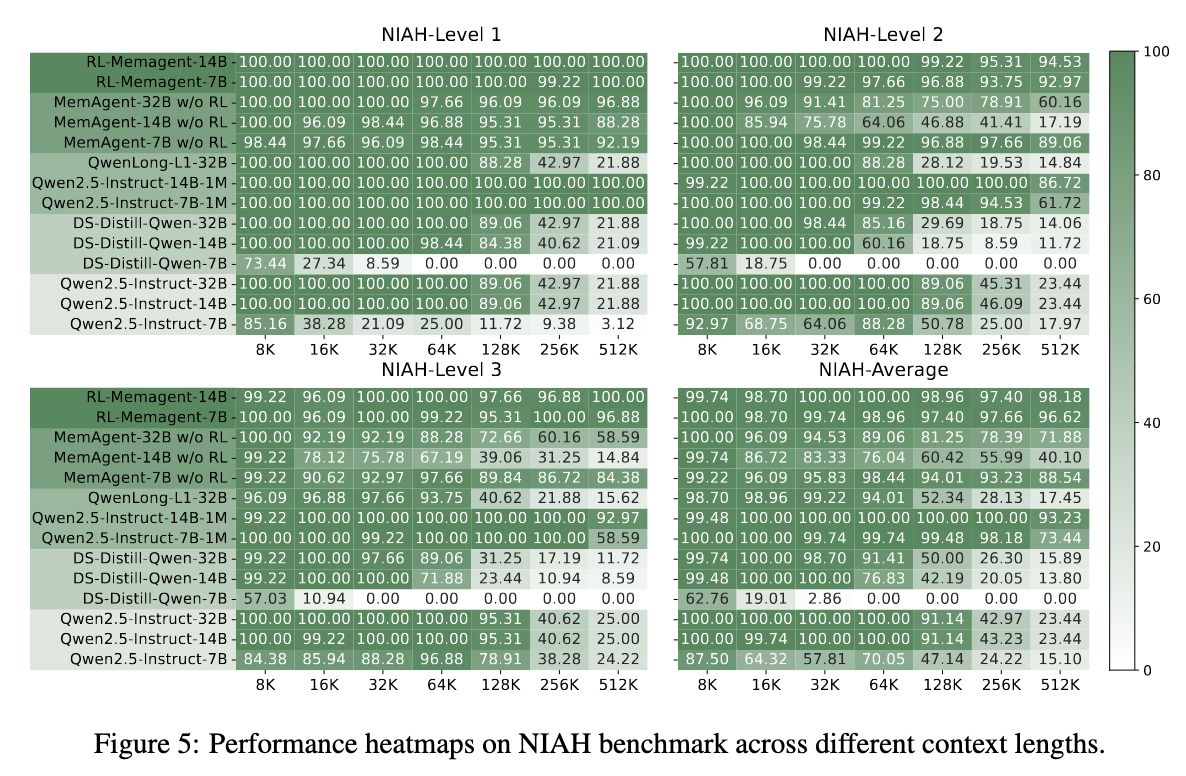 从RULER基准中采用了三个难度递增的NIAH变体。如图5所示,大多数基线模型即使在128K的上下文窗口内也难以保持一致的性能,即使是Qwen2.5-Instruct-1M在512K处也经历了性能下降。尽管RL-MEMAGENT也经历了一些性能波动,但在512K处仅显示出小于5%的最小性能损失。考虑到512K的评估涉及超过100轮的对话,这种稳健的性能尤其值得注意。 ### LongBench-SUM 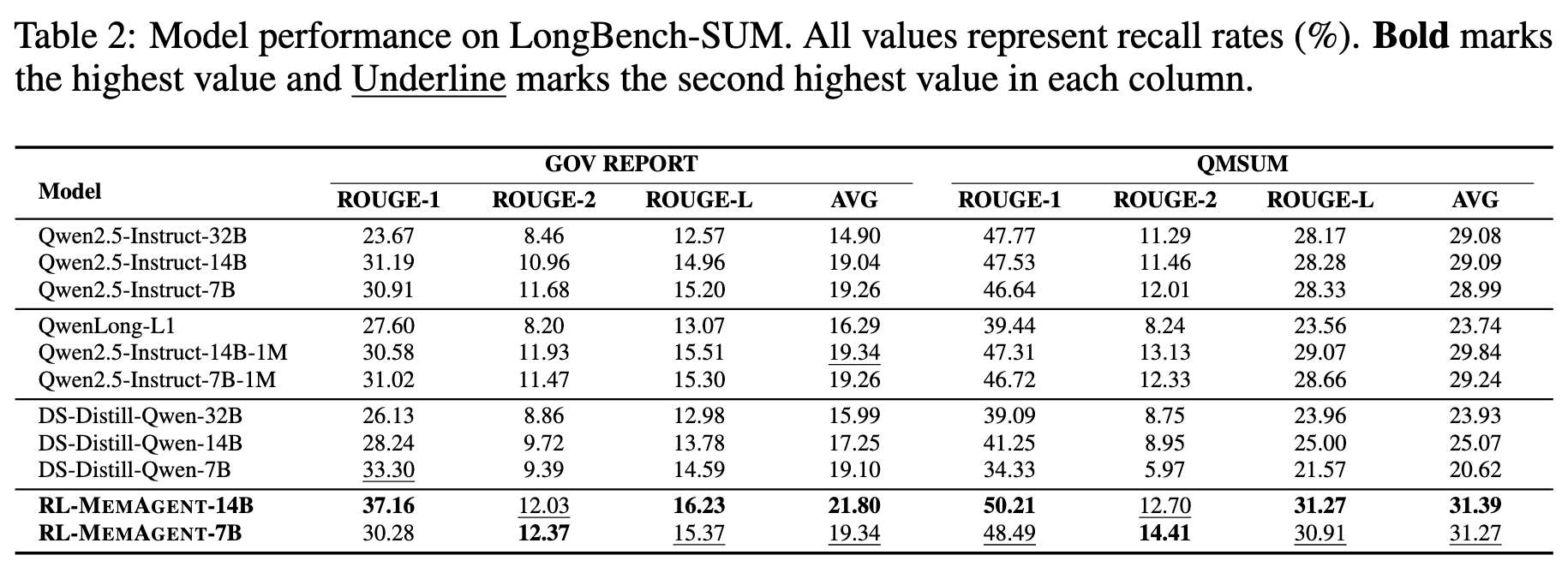 通过ROUGE-{1,2,L}的召回率分数来评估摘要质量。RL-MEMAGENT在几乎所有指标上都达到了SOTA,表明该模型已学会通用的记忆和上下文管理能力,而非仅针对QA任务的特定能力。 ## Ablation Study ### RL Training  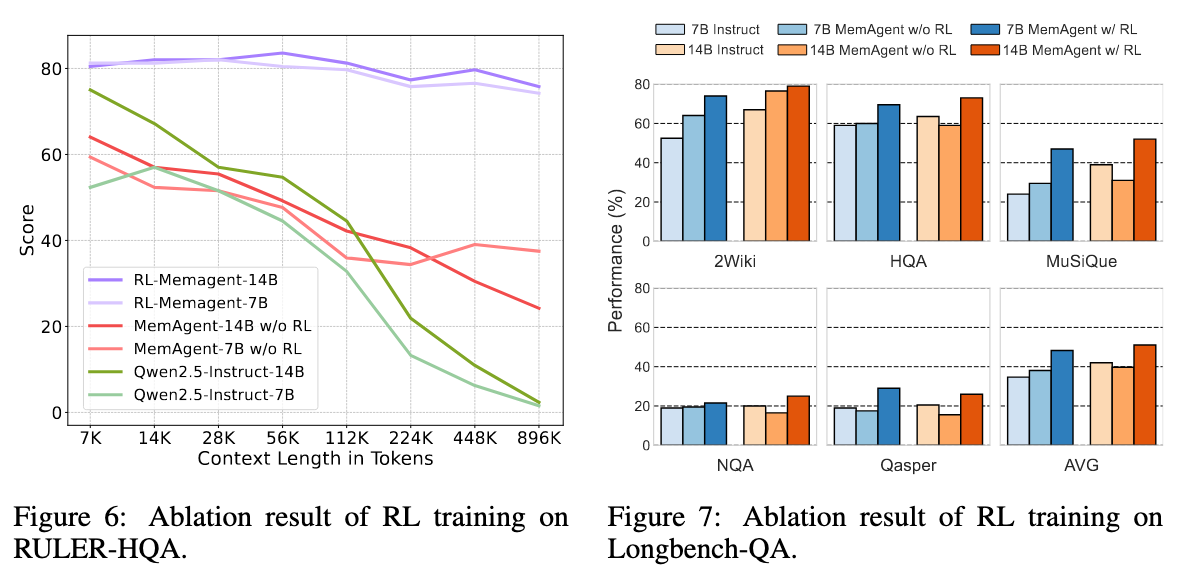 为了研究强化学习的影响,我们进行了消融实验。RULER-HQA和NIAH的结果分别呈现在图6和图5中。没有强化学习训练的MEMAGENT优于骨干模型;然而,随着输入长度的增加,它仍然表现出显著的性能下降。Longbench-QA的结果(图7)表明,直接应用MEMAGENT只会带来微小甚至负面的改进。相比之下,RL-MEMAGENT在两种评估场景中都取得了显著的提升,这表明强化学习训练对于发展可泛化和稳健的记忆能力至关重要。 ### Memory Length 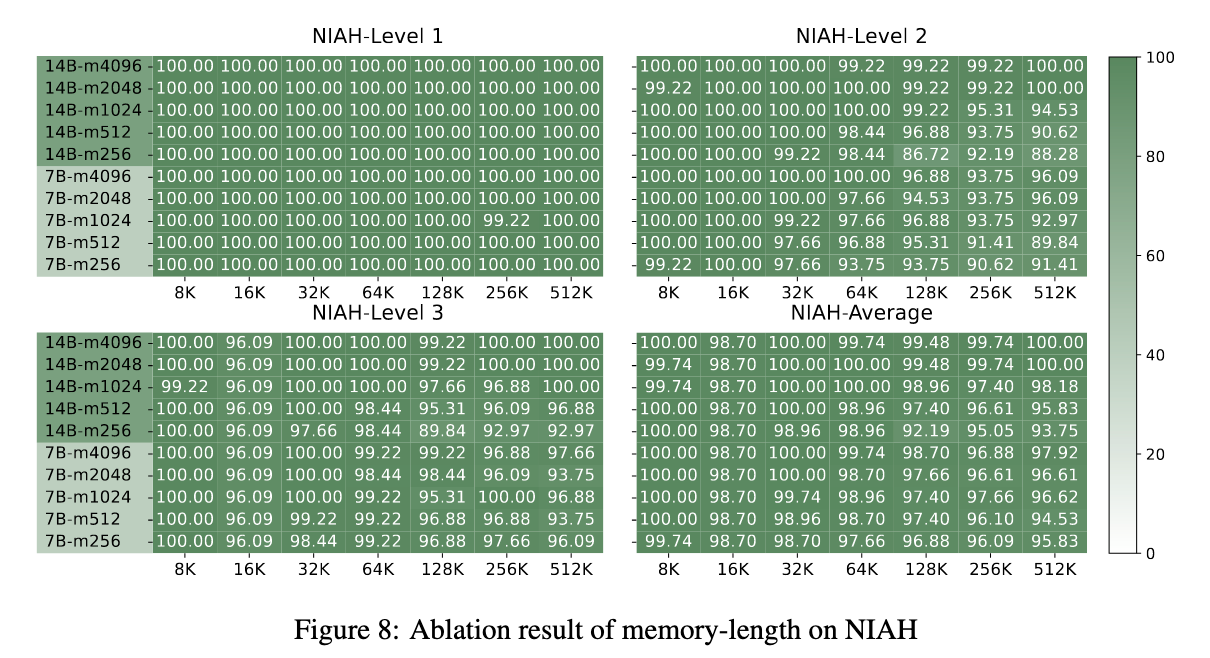 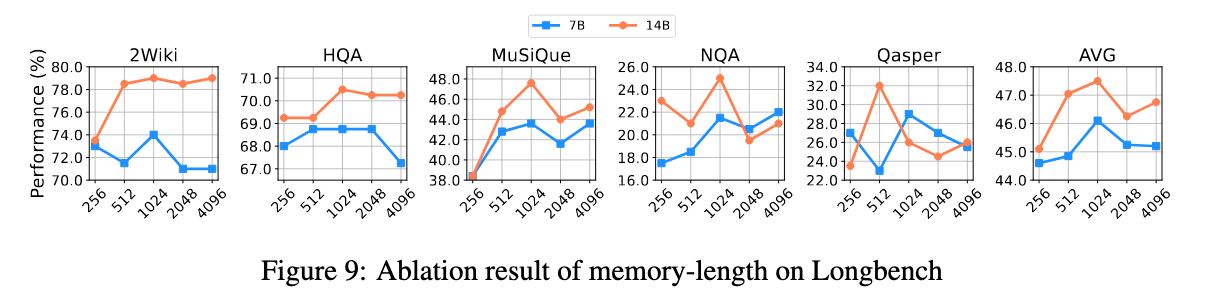 选择合适的MEMAGENT设置涉及某些权衡。较大的记忆大小允许模型存储更多有用信息,但也给记忆管理带来挑战,并增加了冗余的可能性。相反的情况可能导致存储容量不足,使模型缺乏必要的参考。 为了在保持总上下文长度在8,192个token内的同时实现合理的压缩比,根据初步验证结果将MEMAGENT的默认配置设置为使用1,024个token的记忆和5,000个token的上下文块。 为了研究超参数选择的影响,对从256到4096的记忆长度进行了消融研究。结果呈现在图8和图9中,表明我们选择的配置构成了一个合理的平衡点,并且MEMAGENT的性能在不同记忆大小下都是稳健的,进一步检验了改变上下文大小的影响,并观察到了类似的趋势。 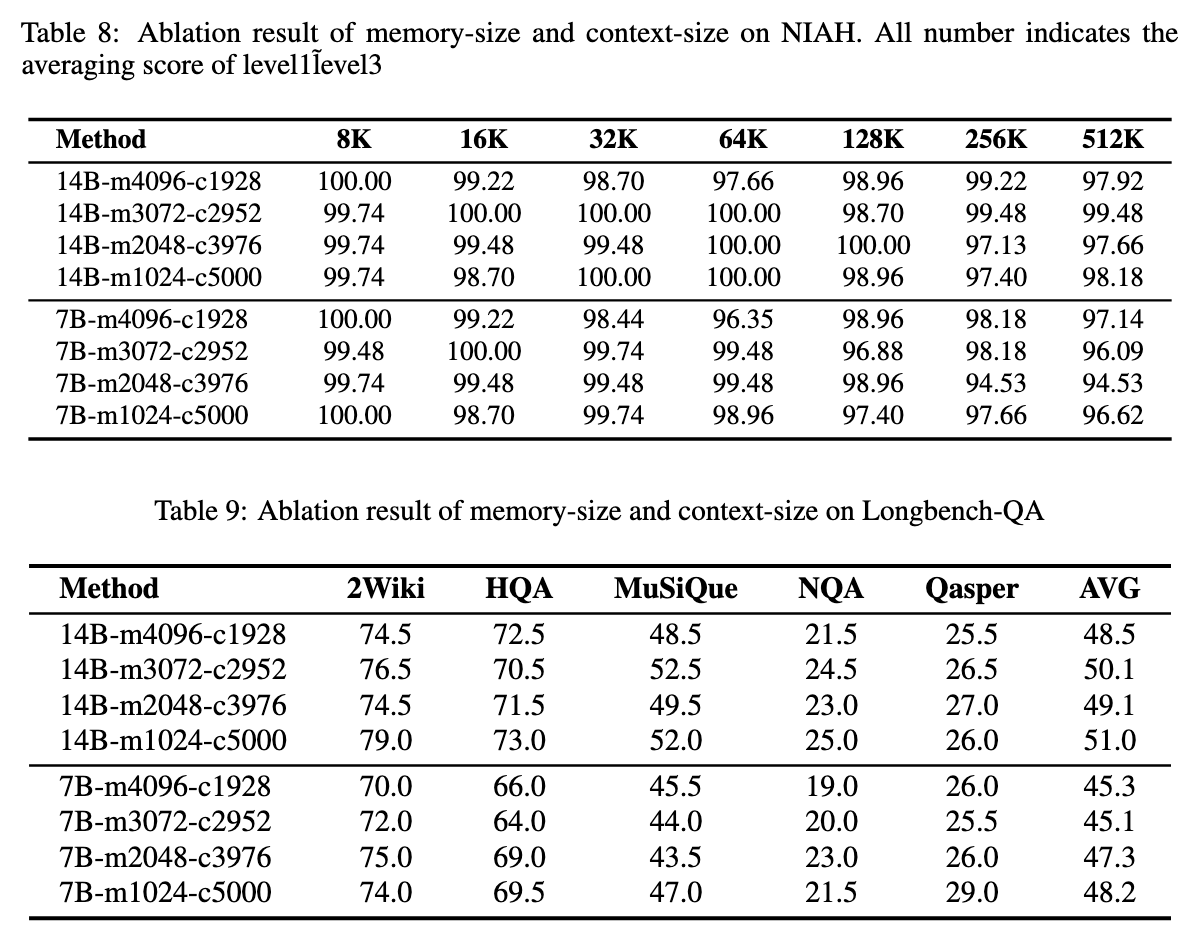 ### Context Distribution 尽管实验表明MEMAGENT可以有效地外推到3.5M个token的长度,仍然希望检验MEMAGENT是否受到诸如信息覆盖和“中部迷失”现象等问题的影响。假设是,克服此类问题是端到端优化的自然结果。在训练期间,模型学会保留和跟踪关键信息,以最大化最终奖励。 为了验证这一假设,我们基于RULER-HQA精心设计了一组探针实验,其中上下文由一些关键信息和许多干扰项组成。我们将关键信息分成两组,并将它们放置在上下文中的不同位置。我们构建了五种设置:(0%,100%)、(20%,80%)、(40%,60%)、(0%,20%) 和 (80%,100%),其中0%表示上下文的开始,100%表示上下文的结束。 例如,在(0%,100%)的情况下,模型在开头看到一条关键信息,而另一条仅在最终记忆更新步骤中才看到。这代表了信息覆盖问题最具挑战性的场景之一。而(40%,60%)可能是具有挑战性的“中部迷失”设置。 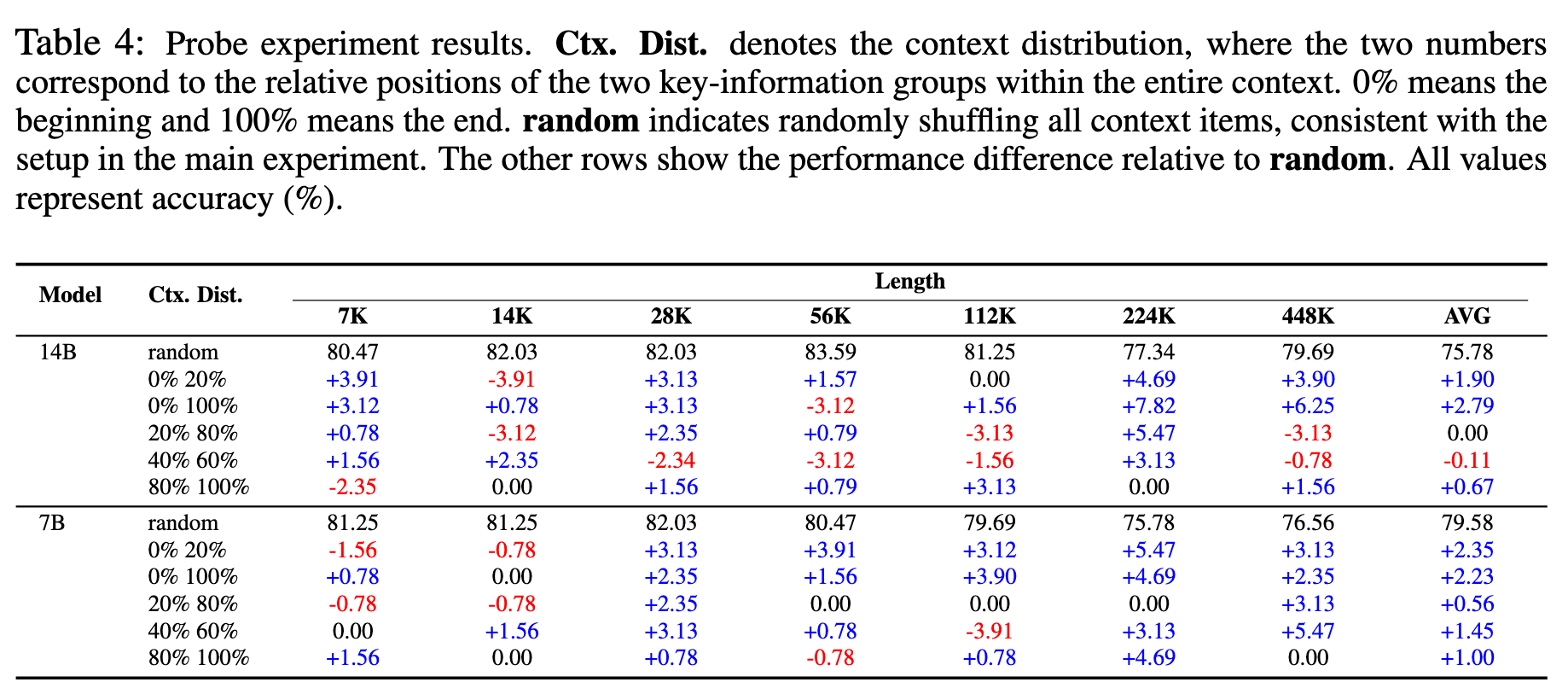 >探针实验结果。Ctx. Dist.表示上下文分布,其中两个数字对应于两个键信息组在整个上下文中的相对位置。0%表示开始,100%表示结束。随机表示随机洗牌所有上下文项目,与主实验中的设置一致。其他行显示了相对于随机的性能差异。所有值表示精度(%)。 MemAgent在所有模式中始终保持稳健,没有表现出任何灾难性的性能下降。 # Related Work # Conclusion 在本文中,我们介绍了MEMAGENT,一种新颖的长上下文方法,它采用经过RL训练的记忆模块,使大语言模型能够有选择地记录相关信息,同时忽略无关的细节。我们的实验表明,当在60K长度的序列上训练时,MEMAGENT表现出卓越的外推能力,仅用8K的上下文窗口就能将其有效上下文扩展到350万token。该模型在多种长上下文任务中取得了最先进的性能。我们的消融研究揭示了基于RL的训练在取得这些成果中的关键作用,以及记忆容量如何影响不同任务类型的性能,为所提出的记忆机制提供了关键见解。我们希望这项工作能为开发更先进的记忆架构和训练策略奠定坚实的基础,从而为显著增强LLM的长上下文能力铺平道路。