相关链接:
Abstract
尝试结合图数据库组织历史记忆,提出新的Agent Memory System,以Agent方式组织记忆。
Introduction
需要记忆系统提供与外部环境的长交互能力

预设的框架与固定的工作流限制了这些系统在新环境中的泛化能力以及在长期交互中保持有效性。
A-Mem 对于每个新记忆构建了综合注释,集成多种表示:包含多个属性的结构化文本属性和用于相似性匹配的嵌入向量。然后,A-MEM分析历史记忆库,基于语义相似性和共享属性建立有意义的连接。
- 自主生成上下文描述,动态建立记忆连接,并基于新体验智能地进化现有记忆。摆脱预定义记忆操作
- 自动触发操作
- 链接生成:识别共享属性、相似上下文描述自动建立记忆之间的连接
- 记忆进化:使现有记忆动态地适应新经历的分析,从而导致更高阶的模式和属性的出现
- 用长期回话数据集全面评估了数据集
Code for Benchmark Evaluation: https://github.com/WujiangXu/AgenticMemory
Code for Production-ready Agentic Memory: https://github.com/WujiangXu/A-mem-sys
Related Work
LLM Memory: 通过密集检索模型或读写记忆结构维护全面的历史记录,MemGPT类似缓存的架构优先处理最近信息,SCM通过记忆流和控制器机制增强LLM维持长期记忆的能力。
RAG
Methodology
使LLM Agent能够在没有预定操作的情况下保持长期记忆。 该系统的设计强调原子记笔记、灵活的链接机制和知识结构的持续演化。
Note Construction
构建结构化的记忆注释,以捕获显式信息和llm生成的上下文理解。集合 中每个记忆笔记表示为: 其中 代表原始交互内容, 是交互的时间戳, 表示LLM生成的关键词,捕获关键概念, 包含LLM生成的用于分类的标签, 代表LLM生成的上下文描述,提供丰富的语义理解, 维护共享语义关系的链接记忆集合。为了给每个记忆笔记赋予超越其基本内容和时间戳的有意义的上下文,利用LLM分析交互并生成这些语义组件。使用作为提示词:
遵循Zettelkasten的原子性原则,每个笔记捕获一个独立的、自包含的知识单元。为了实现高效的检索和链接,通过文本编码器计算一个密集向量表示,该表示封装了笔记的所有文本组件:
通过使用LLM生成丰富的组件,我们能够从原始交互中自主提取隐含知识。多方面的笔记结构 创建了捕获记忆不同方面的丰富表示,促进了细微的组织和检索。此外,LLM生成的语义组件与密集向量表示的结合,既提供了上下文,又提供了计算高效的相似性匹配。
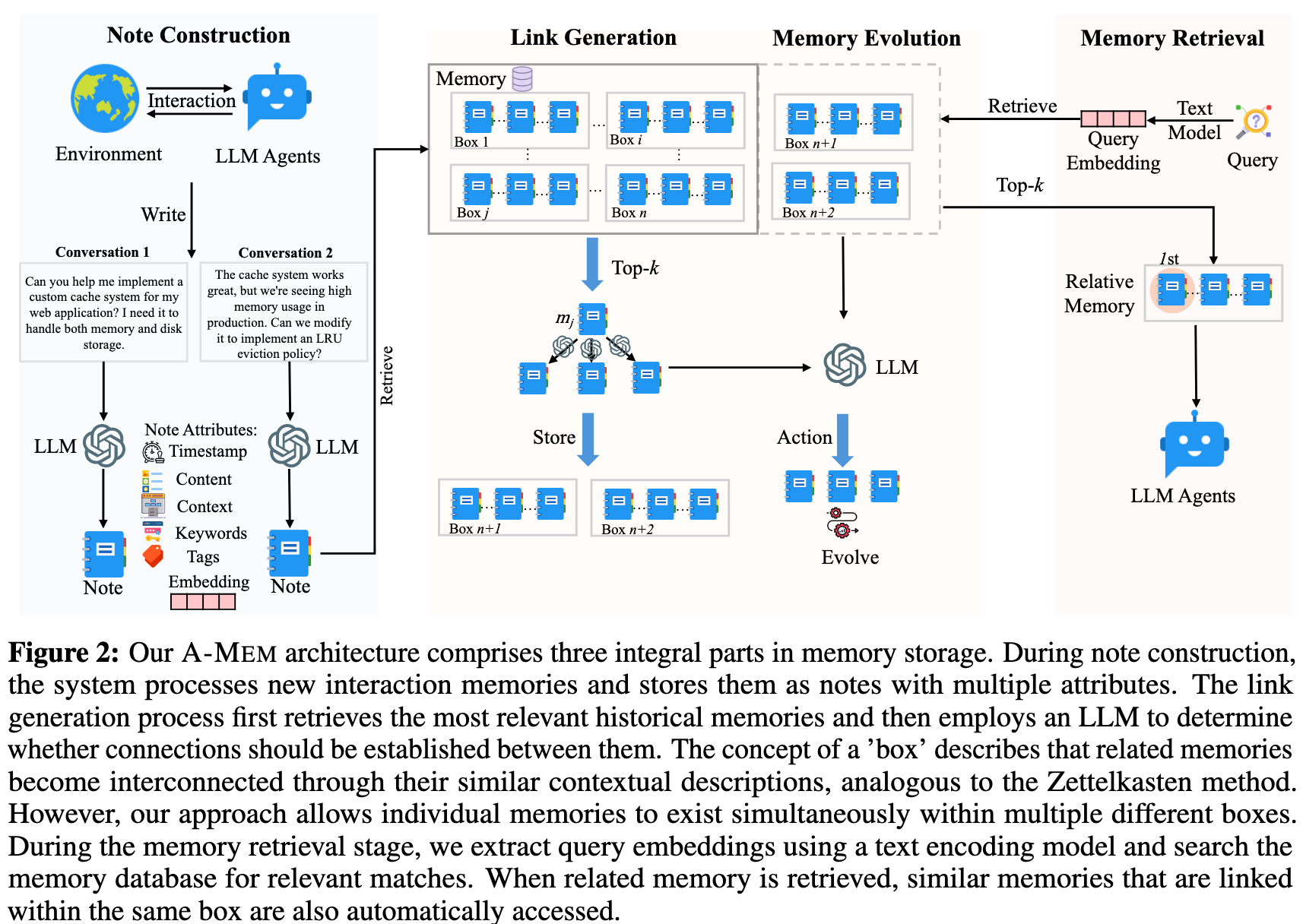
Fig.2 A-MEM架构包括内存存储的三个组成部分。在笔记构建过程中,系统处理新的交互记忆,并将其存储为具有多个属性的笔记。链路生成过程首先检索最相关的历史记忆,然后使用LLM来确定它们之间是否应该建立连接。“盒子”的概念描述了相关记忆通过相似的上下文描述变得相互关联,类似于Zettelkasten方法。然而,我们的方法允许单个记忆同时存在于多个不同的盒子中。在记忆检索阶段,我们使用文本编码模型提取查询嵌入,并在记忆数据库中搜索相关匹配项。当相关的记忆被检索时,链接在同一框内的类似记忆也会被自动访问。
Link Generation
我们的系统实现了一个自主链接生成机制,使新的记忆笔记形成有意义的连接没有预定义的规则。当构造记忆注释被添加到系统中时,我们首先利用其语义嵌入进行基于相似性的检索。对于每个现有的内存笔记,我们计算一个相似度得分: 然后系统识别出k个最相关的记忆: 基于这些候选的最近记忆,我们提示LLM根据潜在的共同属性分析潜在的连接。最终记忆的链接集更新如下: 每个生成的链接的结构为:。通过使用基于嵌入的检索作为初始过滤器,我们能够实现高效的扩展性,同时保持语义相关性。A-MEM 即使在大规模记忆集合中也能快速识别潜在连接,而无需进行详尽的比较。更重要的是,LLM驱动的分析允许对关系进行细致入微的理解,这超越了简单的相似性度量。语言模型可以识别出仅凭嵌入相似性可能不明显的微妙模式、因果联系和概念关联。我们实现了Zettelkasten的灵活链接原则,同时利用了现代语言模型。由此产生的网络根据记忆内容和上下文自然形成,实现了知识的自然组织。
Memory Evolution
为新记忆创建链接后,A-MEM 基于其文本信息以及与新记忆的关系,对检索到的记忆进行演化。对于在最近记忆集合 中的每个记忆 ,我们使用LLM来分析和可能更新其属性,这个过程可以形式化为: 其中 是指导LLM进行记忆演化的提示模板。这个过程允许现有记忆吸收来自新经验的信息,导致其关键词、标签和上下文描述的细化。通过实现这种双向影响——新记忆影响旧记忆,反之亦然——我们的系统创建了一个动态的知识网络,随着更多信息的积累而不断自我完善。这种演化机制确保了记忆表示保持最新,并且能够反映不断变化的上下文和理解。
Retrieve Relative Memory
在推理时,给定一个查询 qq,A-MEM 检索最相关的记忆以增强LLM的响应。首先,我们使用与前面公式相同的文本编码器 计算查询的嵌入 :
然后,使用余弦相似度计算 与所有记忆笔记嵌入 之间的相似度分数: 基于相似度分数检索top-k个最相关的记忆,由于存在相关链接,检索不仅可以返回直接匹配的记忆,还可以通过遍历链接来获取间接相关的记忆,丰富检索到的上下文。
Experiment
Dataset and Evaluation
-
LoCoMo
-
DialSim
-
F1: 平衡精度与召回率来评估答案准确性
-
BLEU: 测量单词与真实答案的重复度来评估回答质量
Implementation Details
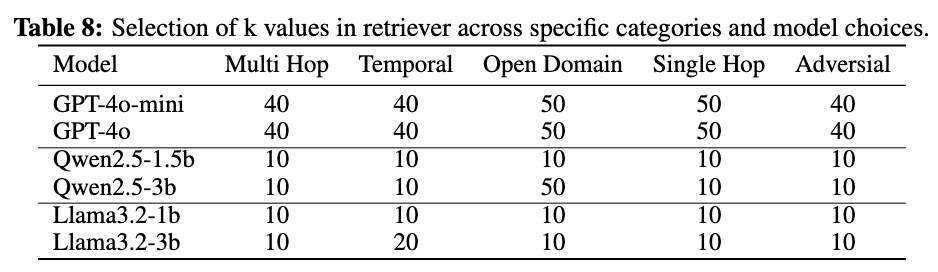
GPT-4o-mini, GPT-4o, Qwen2.5-1.5b, Qwen2.5-3b, Llama3.2-1b, Llama3.2-3b
Sentence-BERT 来生成嵌入 检索参数 kk 在 {10, 20, 30, 40, 50} 中进行调整
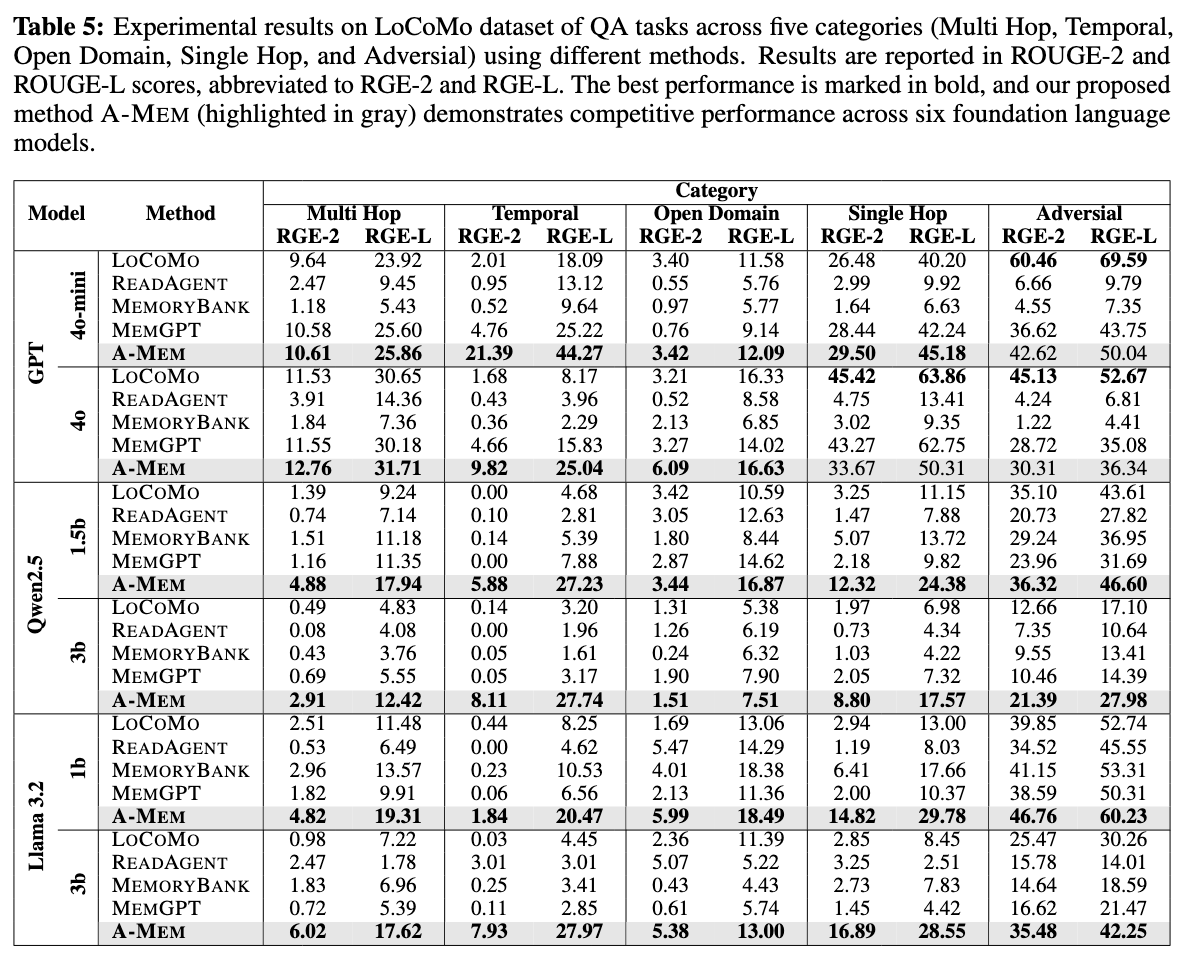
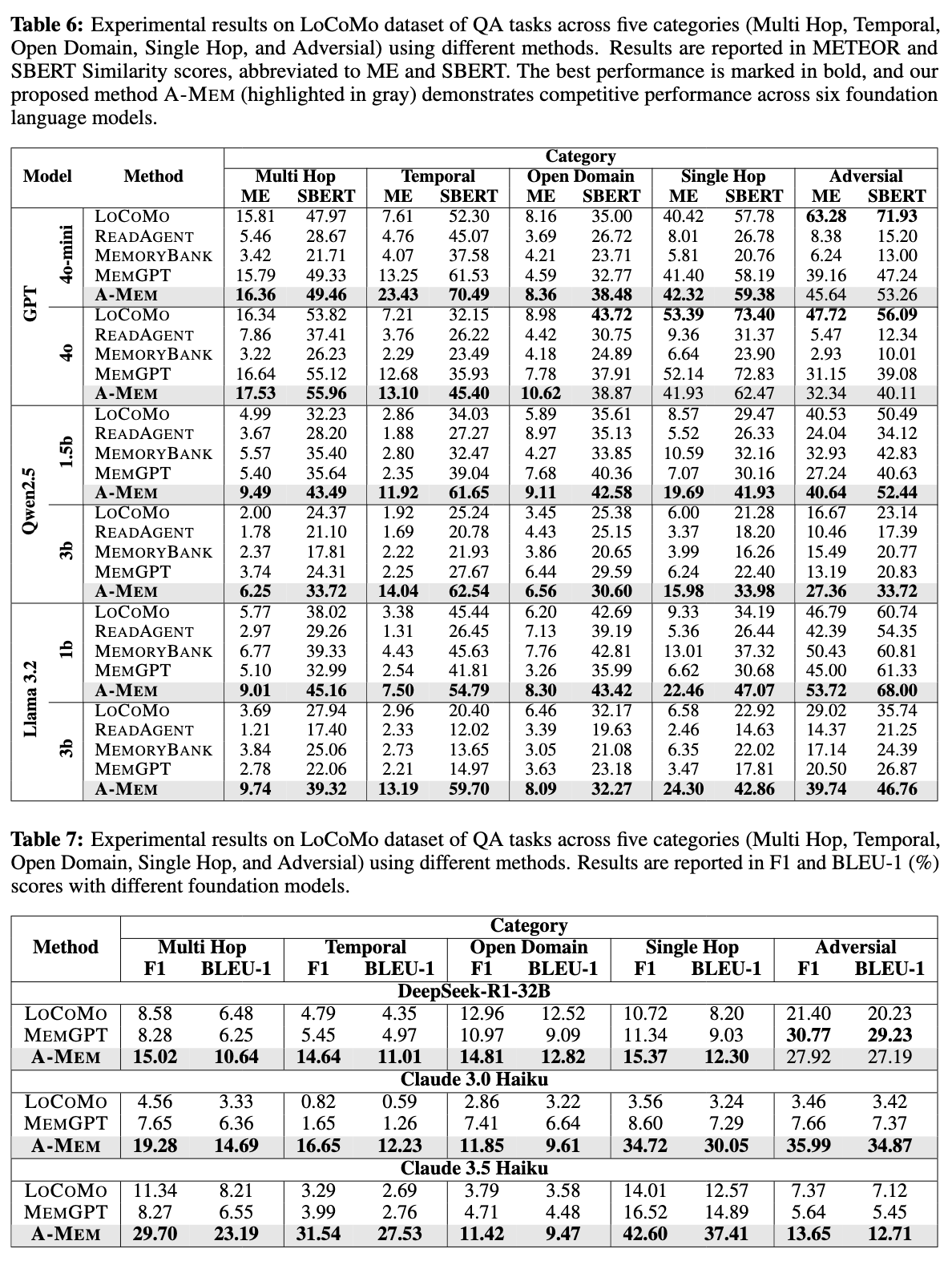
Empirical Results

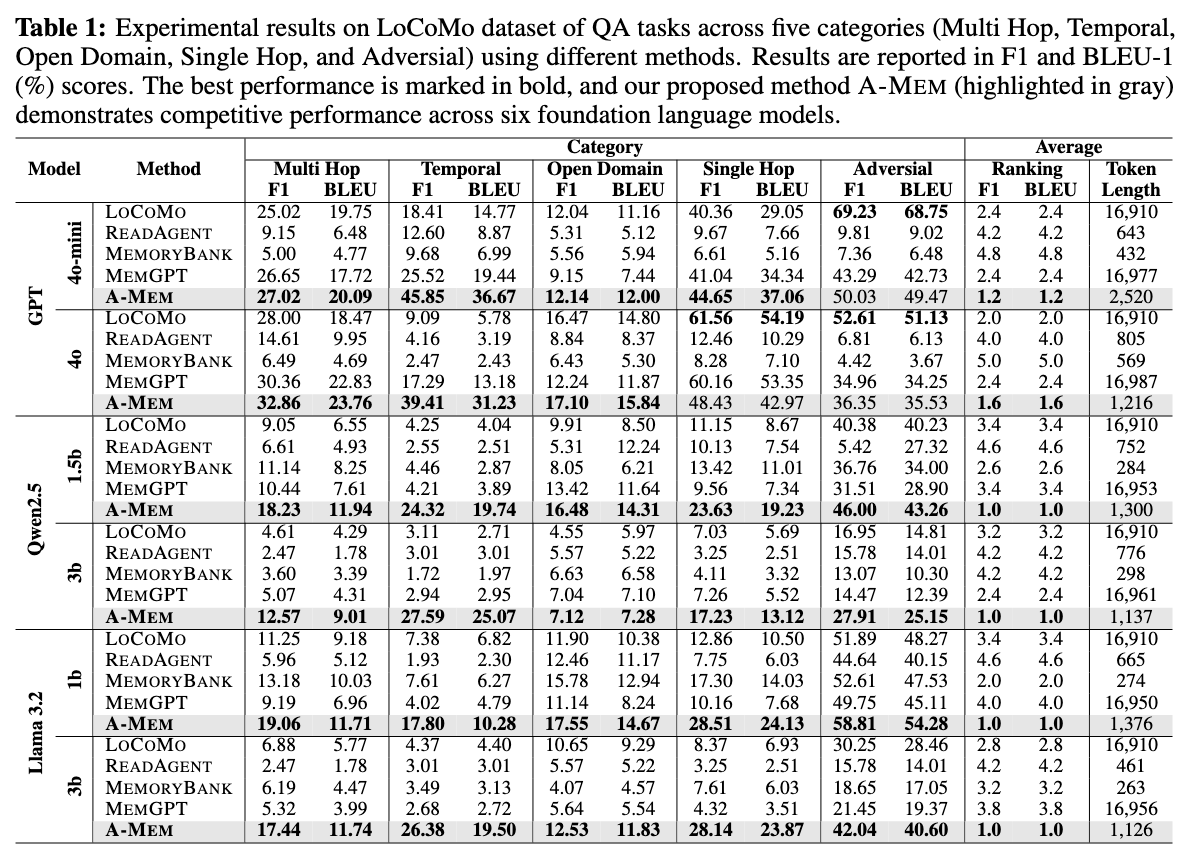
表1展示了在LoCoMo数据集上,针对六个基础模型,使用F1和BLEU-1指标的结果。A-MEM在所有模型和任务类别中始终达到最高或第二高的性能。特别是,在多跳任务中,A-MEM显著优于所有基线。例如,使用GPT-4o-mini时,A-MEM的F1分数为27.02,而LoCoMo为9.65,MemGPT为21.35。这证明了A-MEM在处理需要整合多条信息的复杂推理任务方面的有效性。
表2展示了在DialSim数据集上的结果。A-MEM在所有指标上都取得了最佳性能。与最强的基线LoCoMo相比,A-MEM在F1上提高了35%以上(3.45 vs. 2.55),在SBERT相似度上提高了23%以上(19.51 vs. 15.76)。这些结果证实了A-MEM在更真实的长期对话模拟环境中的优势。
A-MEM在提供强大性能的同时,也展现了显著的计算和成本效率。该系统每次记忆操作大约需要1,200个token,通过我们的选择性top-k检索机制,相比基线方法(LoCoMo和MemGPT需要16,900个token)实现了85-93%的token使用量减少。这种显著的token减少直接转化为更低的运营成本,使得大规模部署在经济上可行。使用GPT-4o-mini时,处理时间平均为5.4秒,而使用本地托管的Llama 3.2 1B模型在单GPU上仅需1.1秒。尽管在记忆处理过程中需要多次LLM调用,A-MEM仍保持了这种成本效益的资源利用,同时在所有测试的基础模型上持续优于基线方法,特别是在复杂的多跳推理任务上性能翻倍。这种低计算成本和卓越推理能力的平衡突显了A-MEM在实际部署中的实用优势。
Ablation Study
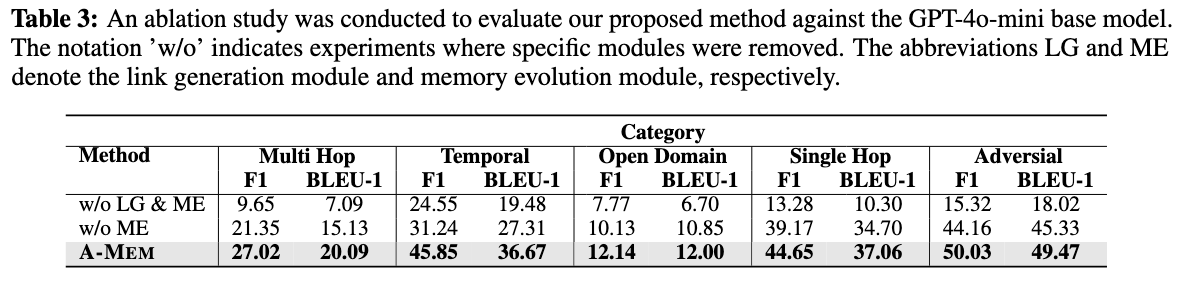
为了评估链接生成(LG)和记忆演化(ME)模块的有效性,我们通过系统地移除模型的关键组件进行了消融研究。当LG和ME模块都被移除时,系统表现出显著的性能下降,特别是在多跳推理和开放域任务中。只有LG激活的系统(w/o ME)显示出中等性能水平,显著优于两个模块都移除的版本,这表明了链接生成在建立记忆连接中的根本重要性。我们的完整模型A-MEM在所有评估类别中持续取得最佳性能,在复杂推理任务中结果尤为突出。这些结果表明,虽然链接生成模块是记忆组织的关键基础,但记忆演化模块为记忆结构提供了必要的细化。消融研究验证了我们的架构设计选择,并强调了这两个模块在创建有效记忆系统中的互补性。
Hyperparameter Analysis
以gpt-4o-mini为基础模型的记忆检索参数k对不同任务类别的影响虽然较大的k值通常通过提供更丰富的历史上下文来提高性能,但超过某些阈值后,收益就会减少,这表明在上下文丰富度和有效的信息处理之间需要权衡。此模式在所有评估类别中都是一致的,这表明平衡上下文检索对于最佳性能的重要性。
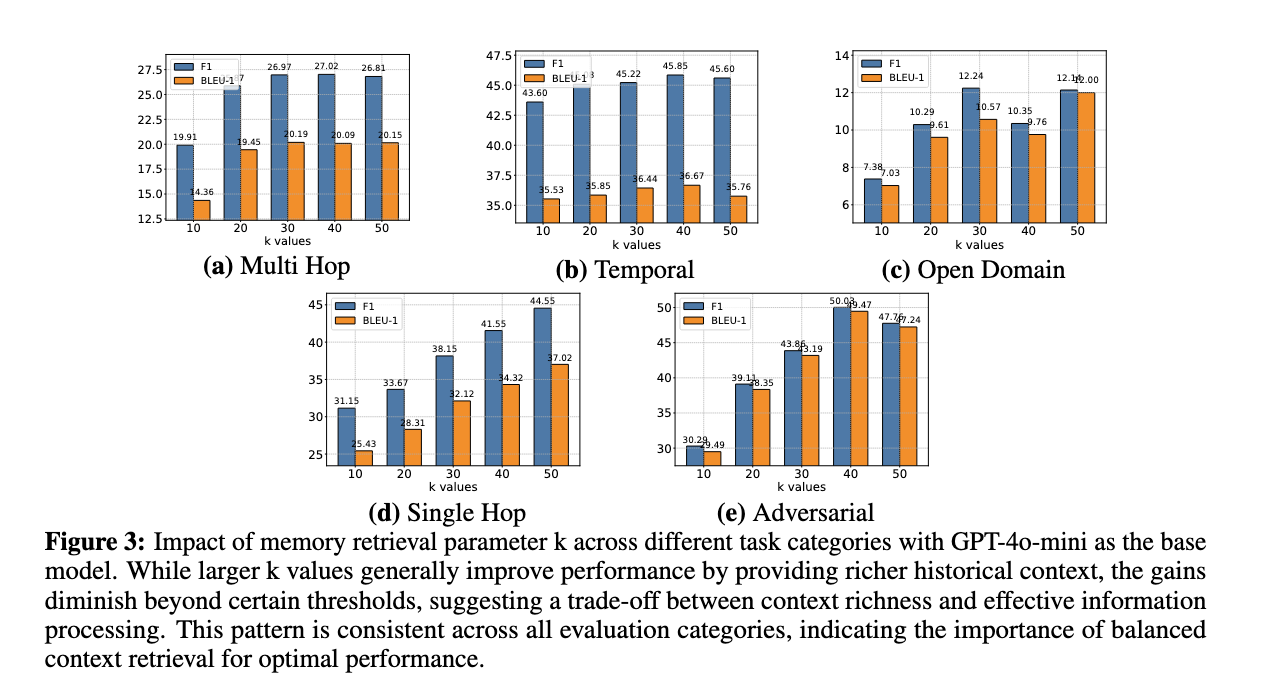
进行了大量实验来分析记忆检索参数k的影响,该参数控制为每次交互检索的相关记忆数量。如图3所示,我们使用GPT-4o-mini作为基础模型,评估了在不同 kk 值(10, 20, 30, 40, 50)下五类任务的性能。结果揭示了一个有趣的模式:虽然增加k通常会带来性能提升,但这种提升逐渐趋于平缓,有时在更高值时会略有下降。这种趋势在多跳和开放域任务中尤为明显。这一观察表明,记忆检索中存在微妙的平衡——虽然较大的 kk 值为推理提供了更丰富的历史上下文,但它们也可能引入噪声,并对模型有效处理更长序列的能力构成挑战。我们的分析表明,适度的k值能够在上下文丰富度和信息处理效率之间取得最佳平衡。
Scaling Analysis
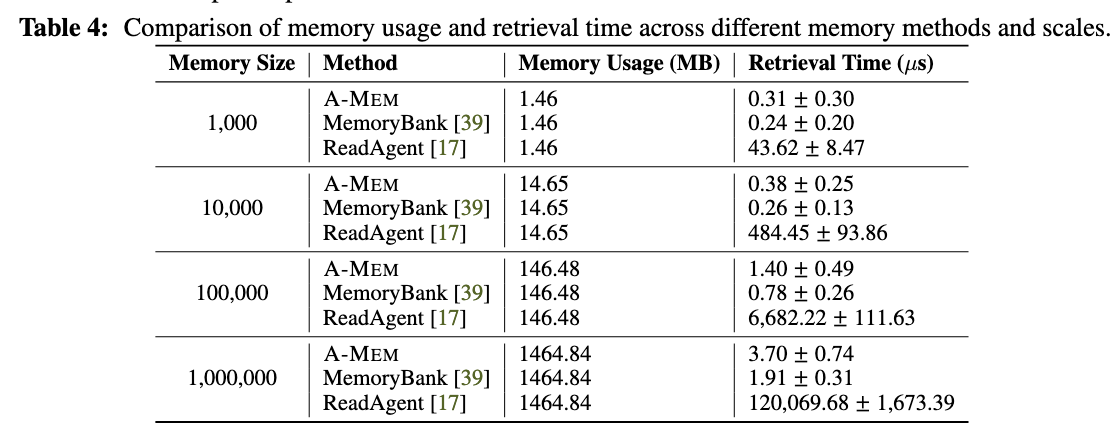
为了评估随着记忆积累的存储成本,我们检验了A-MEM系统与两个基线方法(MemoryBank和ReadAgent)在存储大小和检索时间之间的关系。我们在四个规模点上评估了这三种具有相同记忆内容的记忆系统,每个步骤将条目数量增加10倍(从1,000到10,000、100,000,最终到1,000,000条)。实验结果揭示了关于A-MEM系统扩展特性的关键见解:在空间复杂度方面,所有三个系统都表现出相同的线性内存使用扩展 (O(N))(O(N)),这对于基于向量的检索系统来说是预期的。这证实了与基线方法相比,A-MEM没有引入额外的存储开销。在检索时间方面,A-MEM表现出卓越的效率,随着记忆大小的增长,时间增加极小。即使扩展到100万条记忆,A-MEM的检索时间仅从 0.31μs0.31μs 增加到 3.70μs3.70μs,表现出卓越的性能。虽然MemoryBank显示出略快的检索时间,但A-MEM在保持可比性能的同时,提供了更丰富的记忆表示和功能。基于我们的空间复杂度和检索时间分析,我们得出结论,即使在大型规模下,A-MEM的检索机制也能保持出色的效率。检索时间随记忆大小增长的幅度极小,这解决了大规模记忆系统中的效率问题,证明了A-MEM为长期对话管理提供了一个高度可扩展的解决方案。这种效率、可扩展性和增强记忆能力的独特结合,使A-MEM成为为LLM智能体构建强大而长期记忆机制的重要进步。
Memory Analysis
记忆嵌入的T-SNE可视化显示,在不同的对话中,与基础记忆(红色)相比,A-MEM(蓝色)显示了更有组织的分布。基础内存是没有链路生成和内存演化的A-MEM。
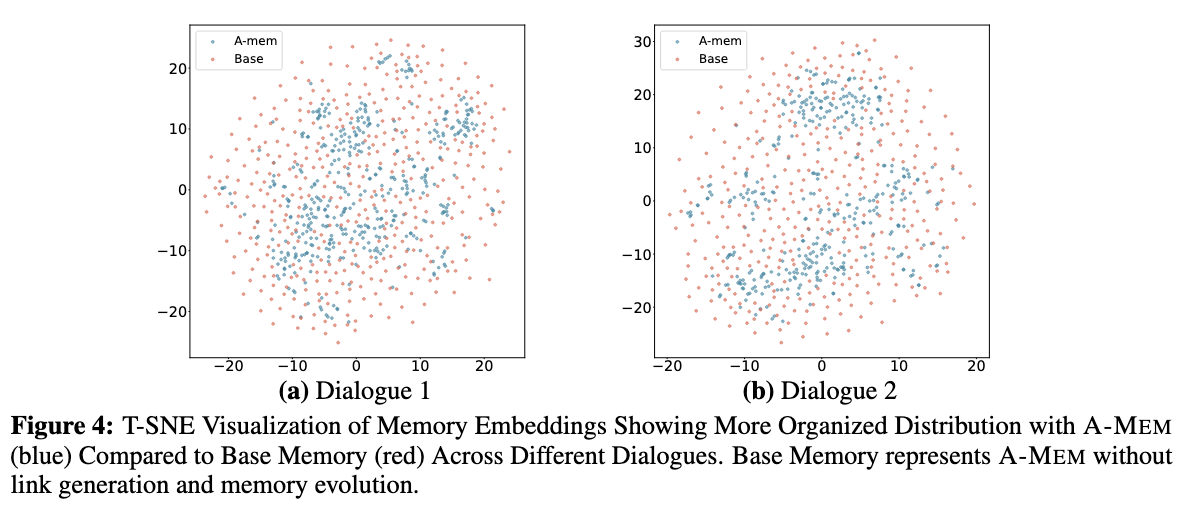
我们在图4中展示了记忆嵌入的t-SNE可视化,以证明我们智能体记忆系统的结构优势。分析从LoCoMo [22]的长期对话中抽样的两个对话,我们观察到A-MEM(蓝色显示)与基线系统(红色显示)相比,始终表现出更连贯的聚类模式。这种结构组织在对话2中尤为明显,中心区域出现了定义良好的聚类,为我们的记忆演化机制和上下文描述生成的有效性提供了经验证据。相比之下,基线记忆嵌入显示出更分散的分布,表明没有我们的链接生成和记忆演化组件,记忆缺乏结构组织。这些可视化结果验证了A-MEM能够通过动态演化和链接机制自主维持有意义的记忆结构。
Conclusions
A-MEM,一种新颖的智能体记忆系统,它使LLM智能体能够动态地组织和演化其记忆,而无需依赖预定义结构
从Zettelkasten方法中汲取灵感,系统通过动态索引和链接机制创建了一个互联的知识网络,能够适应多样化的现实世界任务。该系统的核心架构具有为新记忆自主生成上下文描述,以及基于共享属性与现有记忆智能建立连接的特点。
Limitations
系统动态地组织记忆,但这些组织的质量可能仍然受到底层语言模型固有能力的影响
不同的LLM可能生成略有不同的上下文描述,或在记忆之间建立不同的连接。