相关链接:
Abstract
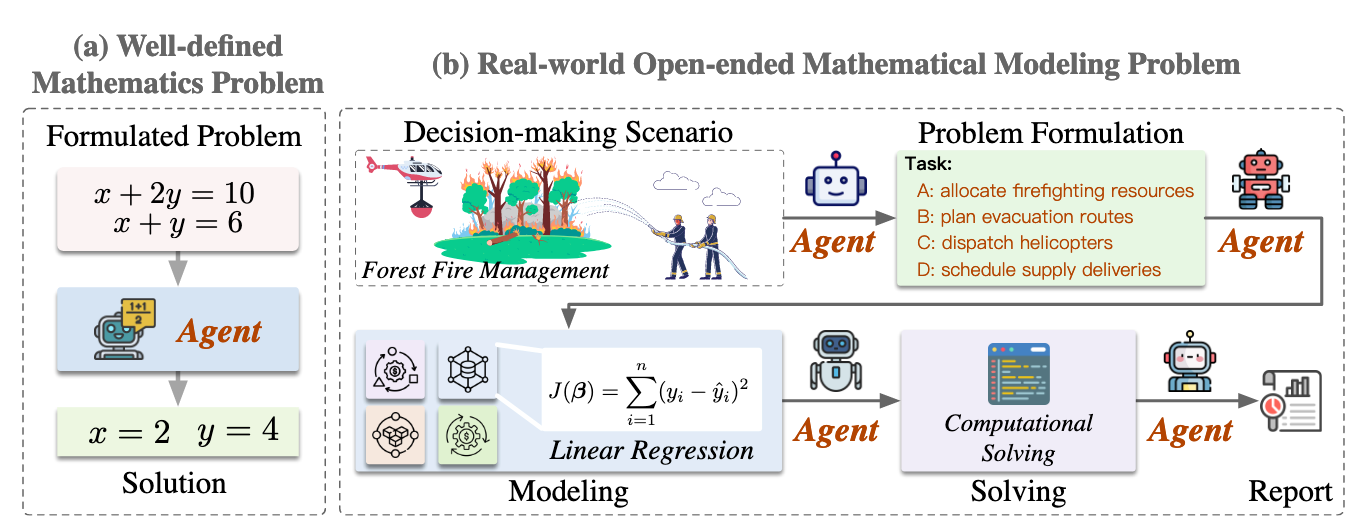
agents must analyze problems, construct domain-appropriate formulations, and generate complete end-to-end solutions.
MM-Bench - Mathematical Contest in Modeling (MCM/ICM) MM-Agent - decomposes mathematical modeling into four stages: openended problem analysis, structured model formulation, computational problem solving, and report generation.
Introduction
- identifying the core problem
- abstracting it into a mathematical form
- constructing appropriate models
- solving them to generate actionable insights.
MM-bench: 10 domains, 8 task types
MM-Agent: analyze problems and decomposes it into subtasks, retrieves suitable methods from HMML and refines its modeling plans via an actor-critic mechanism.
HMML: tri-level knowledge hierarchy encompassing domains, subdomains and method nodes. It encodes 98 high-level modeling schemas that enable both problem-aware and solution aware retrieval of modeling strategies, supporting abstraction and method selection.
Building LLM Agent for Real-World Mathematical Modeling Problems
MM-Bench
Benchmark Construction
Real-world mathematical modeling competitions, such as MCM/ICM.
Using GPT-4o to extract the following elements:
- background information
- problem requirements
- dataset path (the location of the dataset)
- dataset description
- variable description
Task Formation
Problem , agent accesses content to generate a final solution report.
Evaluation
- Analysis Evaluation
- Modeling Rigorousness
- Practicality and Scientificity
- Result and Bias Analysis
HMML Construction
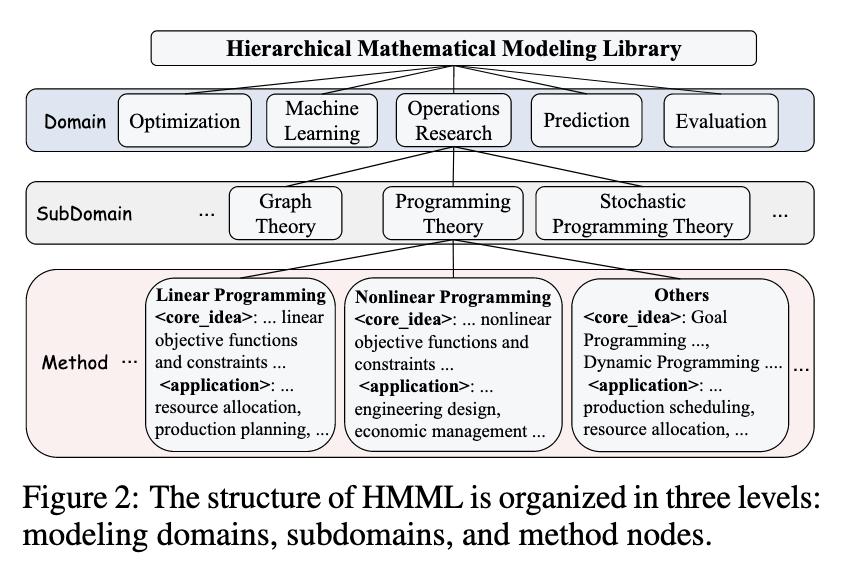
- Domains
- Subdomains
- Method Nodes
MM-Agent
Problem Analysis, Mathematical Modeling, Computational Solving, and Solution Reporting.
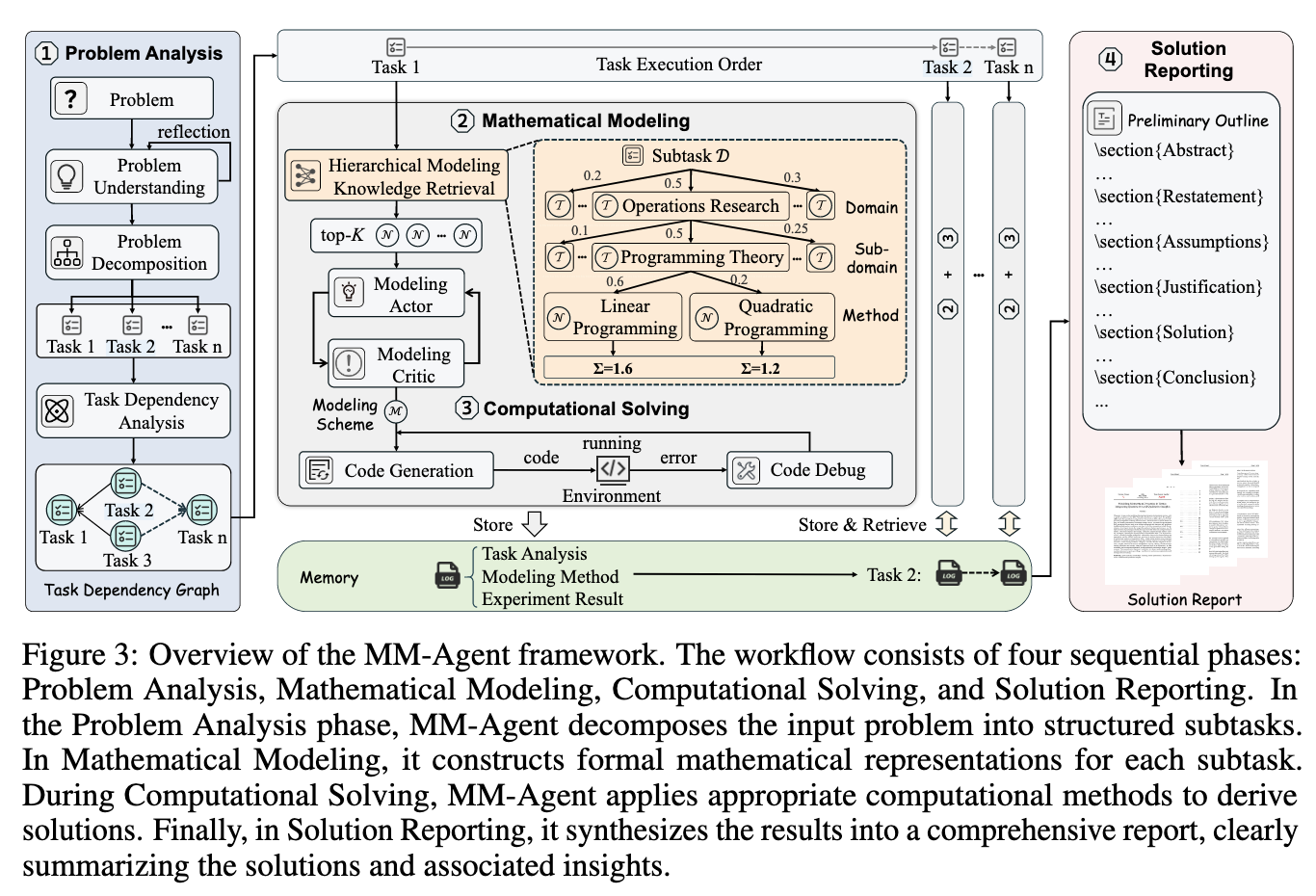
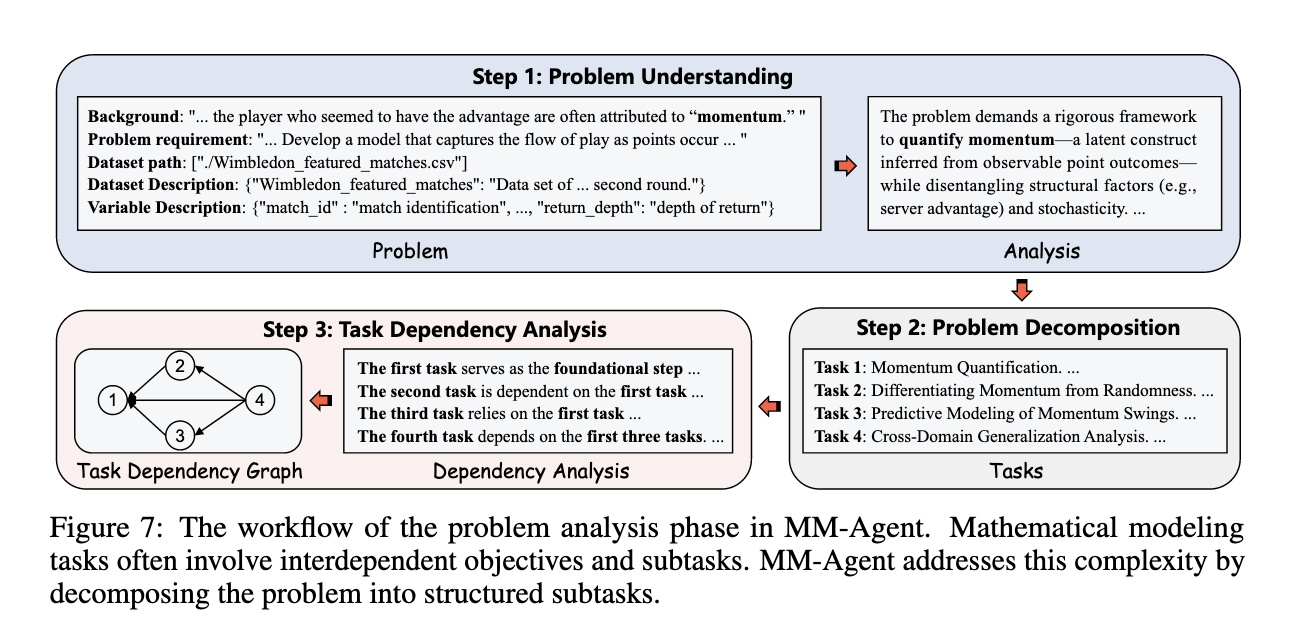
Problem Analysis
abstracting key elements & analyzing relationships
Problem Understanding
设置能迭代反思优化分析的的Analyst Agent
给定建模问题, 编码上下文信息, 表示由 参数化的语言模型,设定大语言模型为
这一过程总的来说可以描述为
Problem Decomposition
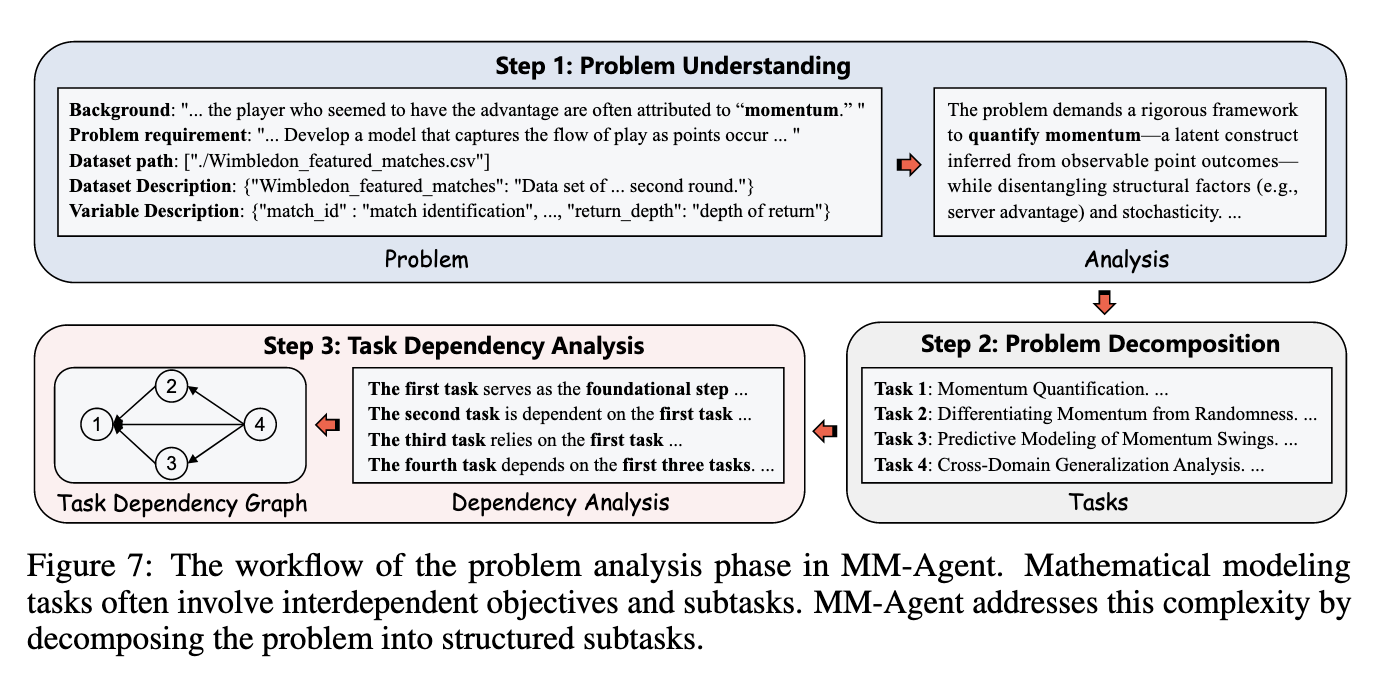
设置用于任务分解的Coordinator Agent
用于表示这一过程, 表示分解的subtasks集
Task Dependency Analysis
分析依赖关系:
基于该结果与关系依赖图构造顺序子任务队列:
历史建模信息被存储在记忆模块中: 为子任务的中间输出,为建模方案,建模代码,输出结果
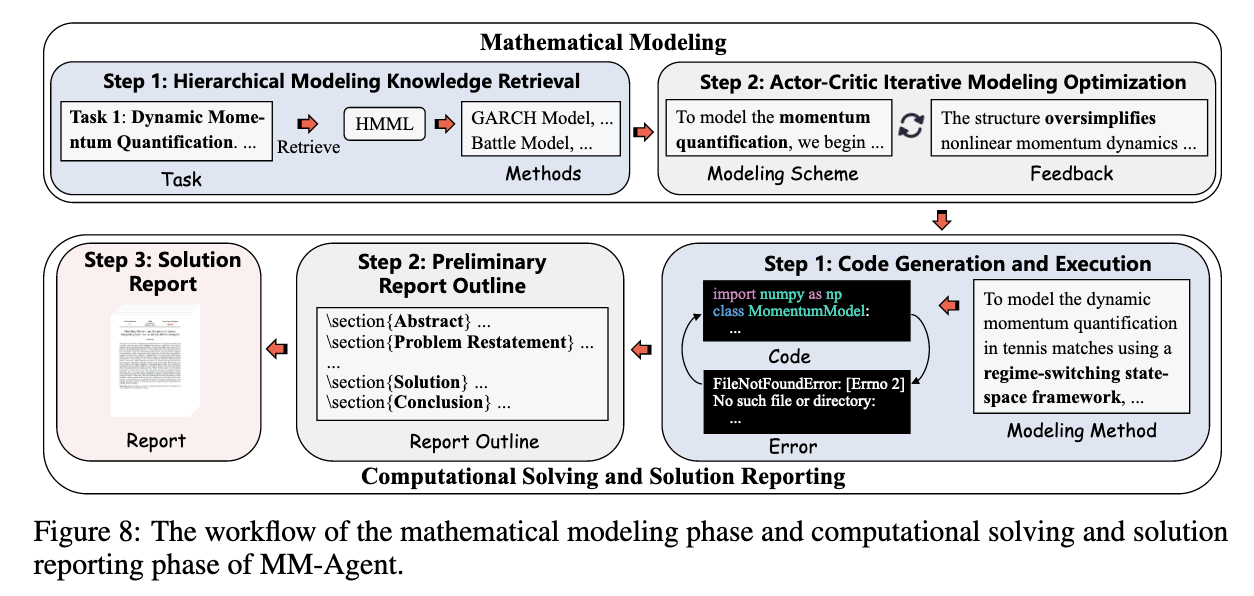
Mathematical Modeling
actor-critic iterative optimization
Hierarchical Modeling Knowledge Retrieval
通过相似度计算来选择相近的子任务与建模方法
与 表示子任务与方法的embedding,采用mGTE作为embedding模型,遍历整个方法层次树之后,通过将每个方法节点自身的相似性与其父节点的相似性相结合来更新每个方法节点的最终得分
最后,选择得分最高的top-K方法节点,记为
Actor-Critic Iterative Modeling Optimization.
检索到的相关知识提供了基本的方法和思想,但是缺乏具体问题所需的深度,通过 actor-critic iterative optimization framework 以实现。
对于问题,coordinator agent从基于依赖图谱的记忆模块检索相关的依赖资源,与 结合。
actor 生成初始建模方案: , 为modeling prompt critic 评估建模质量以及提供目标反馈:
后续迭代:
Computational Solving and Solution Reporting
重点是求解数学模型,生成全面的方案报告。agent自主编写代码,使用MLE-Solver[68]进行计算实验,迭代生成、测试和细化代码,以确保高效准确的执行。实验完成后,agent将生成结构化的解决方案报告,总结建模方法、实验结果和关键发现。
Code Generation and Execution.
设计programmer agent根据建模方案生成相应代码:
生成代码后,将编译程序以检查运行时错误。如果编译成功,则返回实验结果。如果代码编译失败,代理将通过分析最后一个错误消息并进行必要的更正来尝试在迭代中修复它。
任务完成后更新agent记忆:
Preliminary Report Outline
在完成所有任务后,报告代理编写解决问题过程的综合摘要。第一步是为数学建模报告构建一个结构化的大纲。该大纲建立了报告的框架,将其组织为八个关键部分:摘要、问题重述、模型假设、假设的证明、符号和定义、问题分析、解决方案和结论。为了确保清晰和连贯,大纲集成了适当的LaTeX格式,便于无缝编译和进一步改进。通过系统地组织内容,为深入而有序的最终报告提供了坚实的基础。
Solution Report
一旦建立了大纲,报告代理使用专门的命令逐步改进报告,利用任务协调器代理的内存.在合并任何修订之前,系统编译LaTeX代码以确保其正确运行,保持文档的完整性。通过一系列反复的编辑,代理保证报告符合质量、一致性和学术严谨性的必要标准。
Experiments
Experimental Setup
Baselines
- Human Team
- DS-Agent (Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, and Jun Wang. Ds-agent: Automated data science by empowering large language models with case-based reasoning. In ICML, 2024)
- ResearchAgent(Qian Huang, Jian Vora, Percy Liang, and Jure Leskovec. Benchmarking large language models as AI research agents. CoRR, abs/2310.03302, 2023.)
- Agent Laboratory(Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using LLM agents as research assistants. CoRR, abs/2501.04227, 2025.)
Experimental Implementation
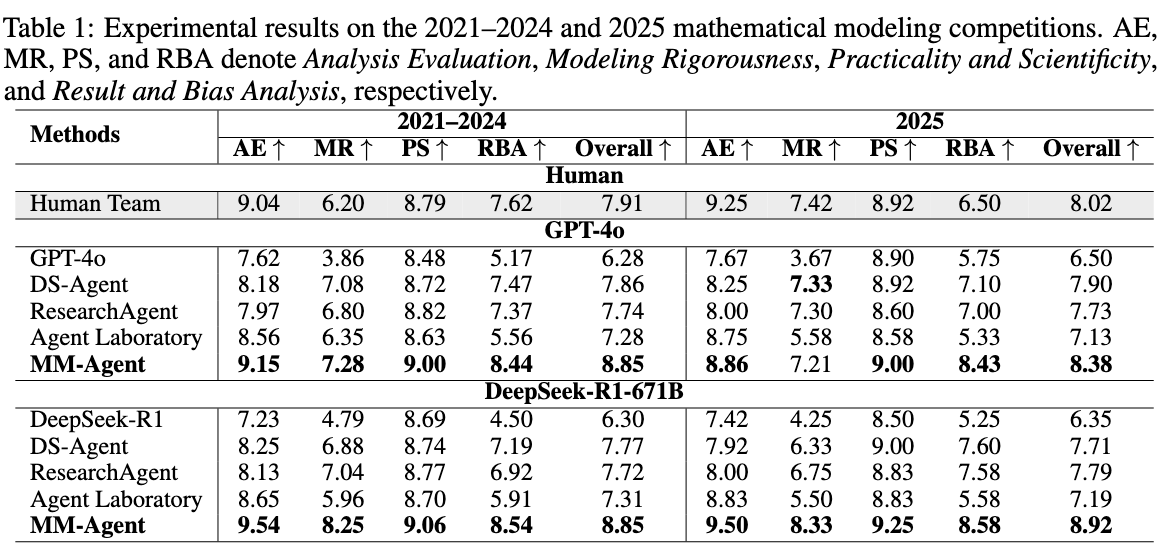
从过去五年(2021-2025)中选择数学建模问题的子集作为测试集,确保问题类型和领域的多样性以支持代表性评估。该子集总共包含 32 个问题。为了减轻大语言模型预训练中潜在的数据泄漏,将 2021-2024 年的问题与 2025 年的问题分开评估。
model: GPT-4o & Deepseek-R1 evaluation: 基于 GPT-4o 的自动评分与人工审查
Experimental Results
- 直接应用基础模型(GPT-4o 或 DeepSeek-R1-671B)而不进行智能体级别的编排会导致显著较弱的性能,特别是在 MR 和 RBA 方面。这一差距突显了大语言模型在处理现实世界建模任务所需的开放式、结构化推理方面的不足,并突显了结构化基于智能体的工作流的必要性。
- MM-Agent 始终优于所有基线智能体,在 GPT-4o 和 DeepSeek-R1-671B 主干下都实现最高的总体分数。
- 基于DeepSeek-R1-671B的智能体超越了gpt-4o, MM-Agent在建模严谨性和结果与偏差分析方面表现出明显的进步,表明在更大的模型中具有更强的推理能力。
- 人类团队仍然是强有力的竞争者,在大多数指标上优于所有基于大语言模型的智能体,除了MM-Agent,突显了任务的复杂性和MM-Agent接近人类的建模能力。
- 2025 年的结果与 2021-2024 年的结果密切相关,表明强时间一致性。这种鲁棒性减轻了对潜在数据泄漏(例如,记忆解决方案)的担忧,并进一步支持 MM-Agent 执行真正建模而非过拟合的结论。
Ablation Study and Further Analysis
Contribution of Key Components
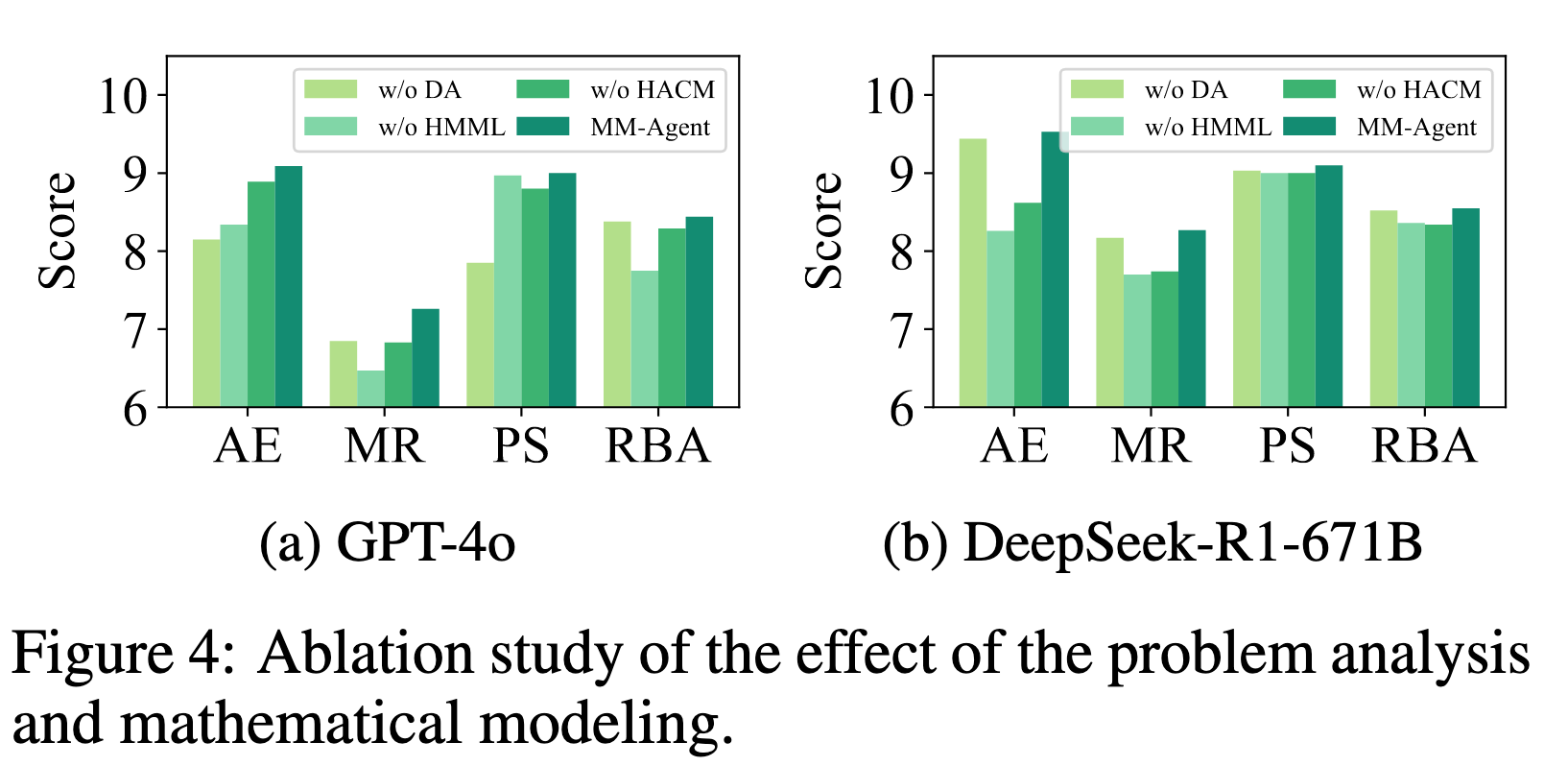
- ask dependency analysis (DA)
- the Hierarchical Mathematical Modeling Library (HMML)
- hierarchical actor-critic modeling (HACM)
在四项评估指标下,MM-Agent始终优于gpt-4o和DeepSeek-R1-671B主干的所有消融变体。
Cost Efficiency Analysis
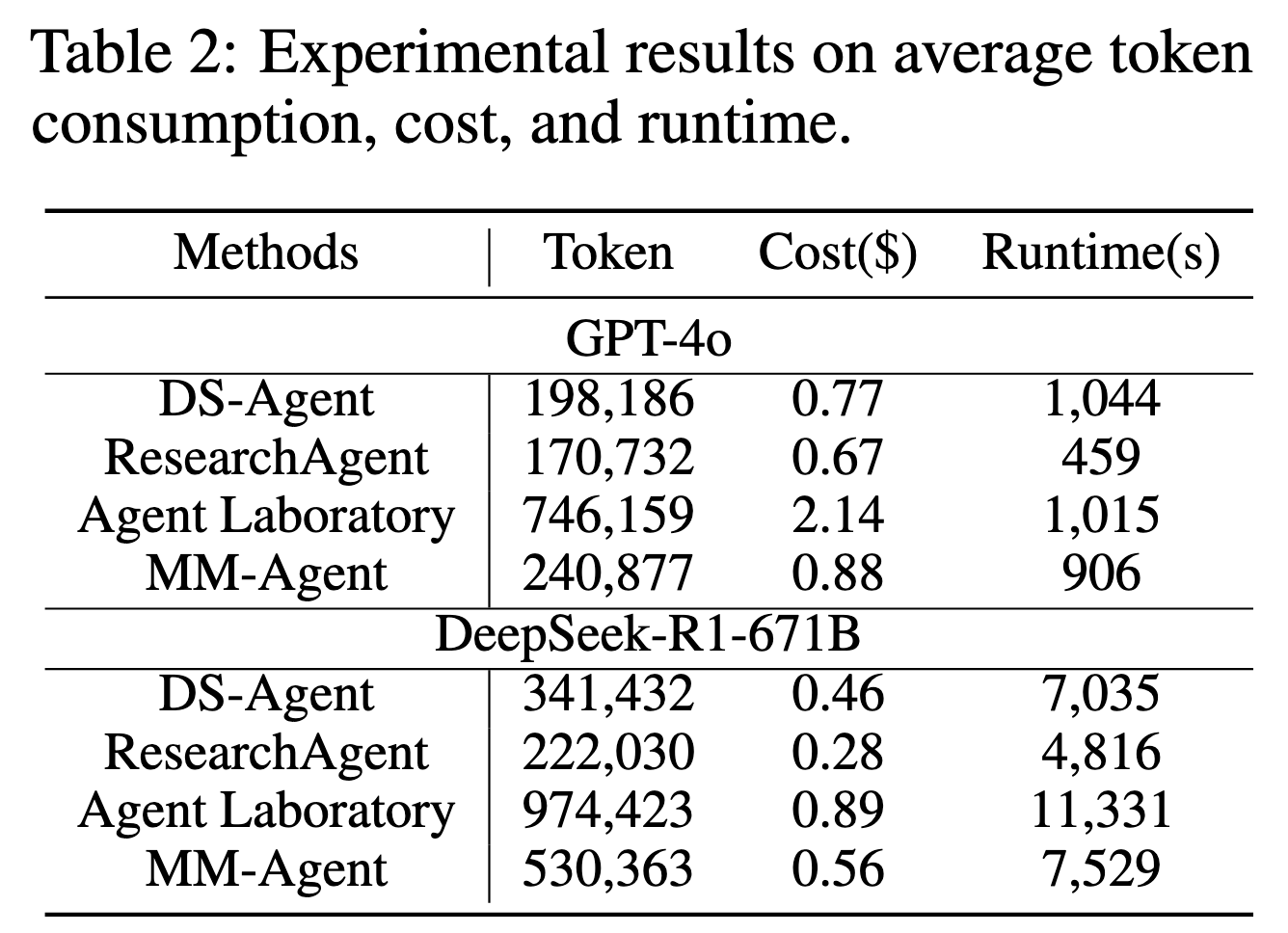

MM-Agent的性能与DS-Agent和ResearchAgent相当,计算成本和运行时间相当。与Agent Laboratory相比,它在大幅降低成本和执行时间的同时实现了更高的性能,突出了其可扩展性和实际可行性。
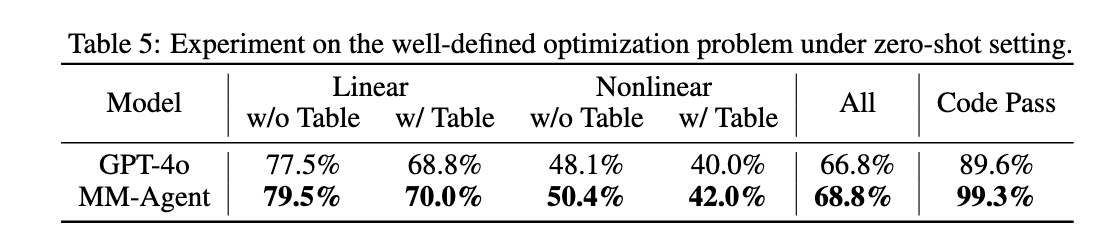
Experiments on Well-defined Mathematical Optimization Problems
为了补充MMBench的开放式重点,对MM-Agent进行了定义良好的数学优化任务评估,包括线性和非线性规划。在这种情况下,智能体接收完整的问题说明(如变量、目标函数和约束),并直接输出数值解。由于这些任务有已知的基础真值答案,因此准确性可以作为直接的性能指标,在OPTIBENCH数据集上进行了实验,详细结果如下图所示。在zero-shot设置中,MM-Agent在所有子任务中始终优于gpt-4o,展示了对配方优化问题的稳健泛化。
附录
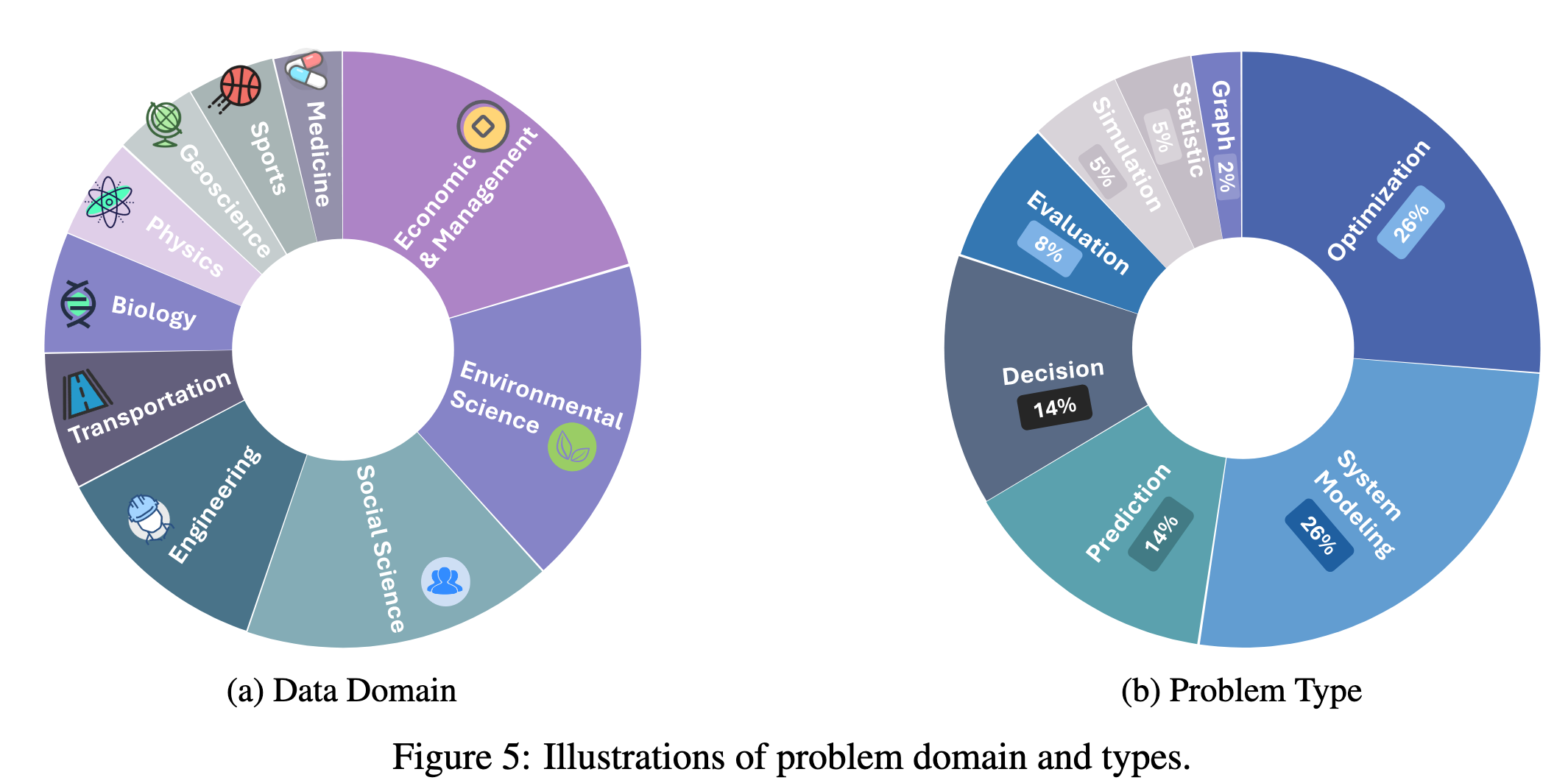
MM-Bench consists of 10 domains, 8 task types (e.g., decision, prediction, evaluation et al.), and a total of 111 problem samples
Baseline: 我们将MM-Agent与人类团队竞赛解决方案和现有的基于llm的agent进行了比较。由于之前没有专门解决数学建模问题的工作,我们采用了为自主研究设计的其他llm代理来解决这些问题。具体来说,我们的基线包括:(1)人类团队,使用来自现实世界数学建模竞赛的原始解决方案,其中团队至少获得荣誉奖。这些屡获殊荣的解决方案可作为基准参考;(2) LLM,直接使用LLM生成数学建模解;(3) DS-Agent,一个专门用于自动化数据科学任务的LLM代理。我们采用基于案例推理的核心设计来解决数学建模问题;(4) ResearchAgent,一个基于llm的代理,旨在使研究工作流程自动化并产生研究想法。我们将其与机器学习代理集成,以增强其数学建模能力;(5)代理实验室,一个基于法学硕士的框架,旨在通过文献综述、实验和报告撰写阶段指导研究过程,从而加速科学发现。对于Agent Laboratory, Agent在arXiv上搜索相关的论文来识别数学建模方法,然后使用这些方法来构建其管道来解决建模问题。